企业架构单点Mysql数据库服务器
学习目标和内容
- 能够实现虚拟机的克隆复制
- 能够配置新克隆机的网卡并启动
- 能够实现业务数据库的迁移
- 能够实现业务代码修改连接数据库
- 能够部署配置phpMyAdmin工具
- 能够了解MySQL优化方向
一、背景描述及其方案设计
1、业务背景描述
时间:2009.6-2010.9
发布产品类型:互联⽹动态站点 商城
⽤户数量: 2000-4000(⽤户量猛增 翻了4倍)
PV : 8000-50000(24⼩时访问次数总和)
QPS: 50-100*(每秒访问次数)
DAU: 200-400(每⽇活跃⽤户数)
数据量翻倍了,使用数据库的次数增多,数据库连接也变多了。之前LNMP单点服务器机构中,ningx、php、mysql之间存在资源(cpu、内存)争抢[等待],最终,用户访问请求返回时间变长了,用户直观体验,网站访问慢了。
模拟运维设计方案
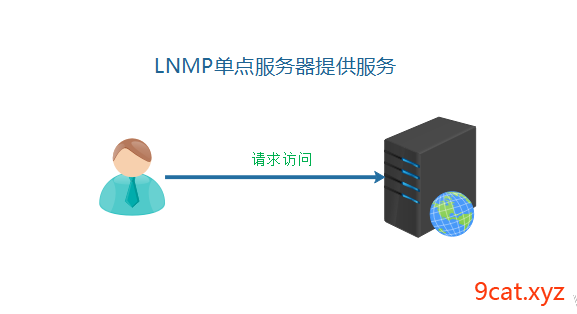
之前已经搭建好的业务架构
升级后的业务架构
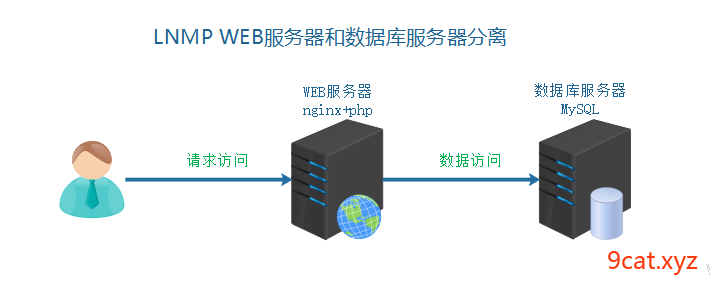
二、数据服务器迁移部署
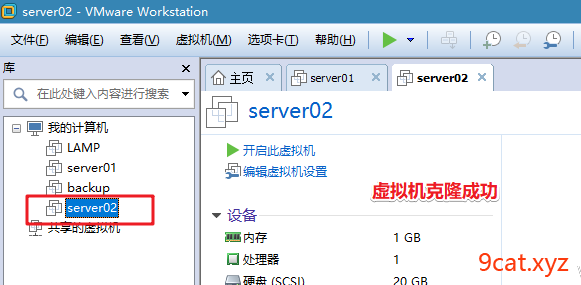
1、克隆复制虚拟机
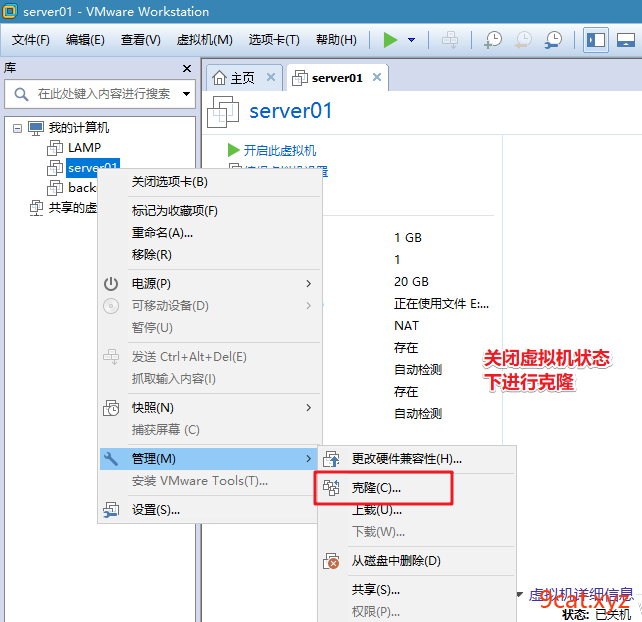
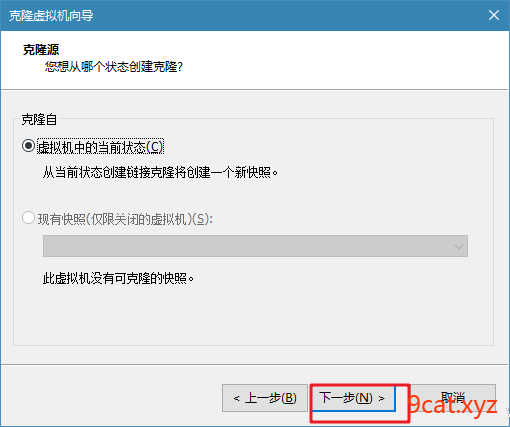
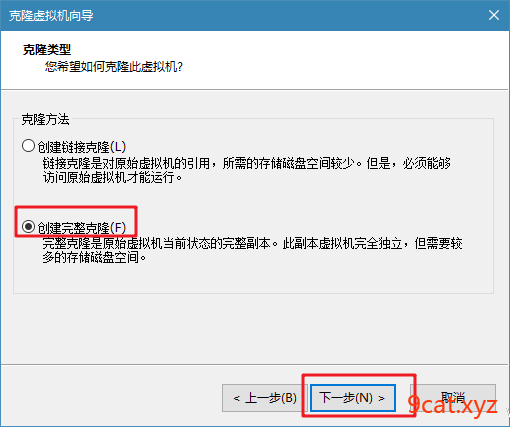
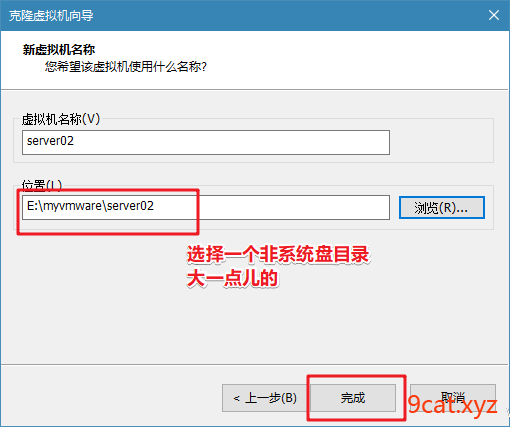
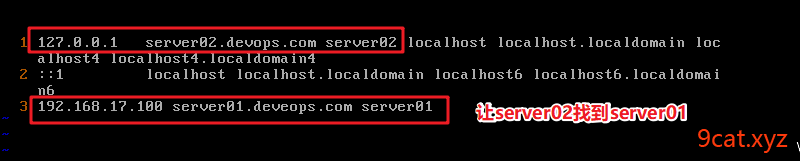
2、配置FQDN
①/etc/hosts
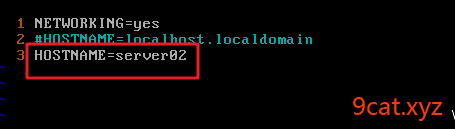
②/etc/sysconfig/network
③查看一下配置效果
hostname hostname -f
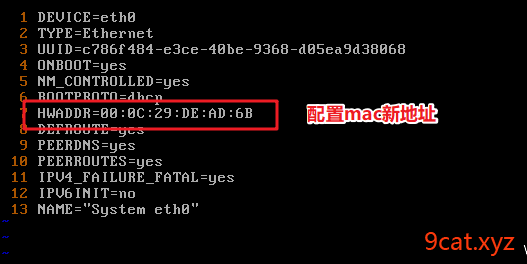
配置新虚拟机的网卡
问题:
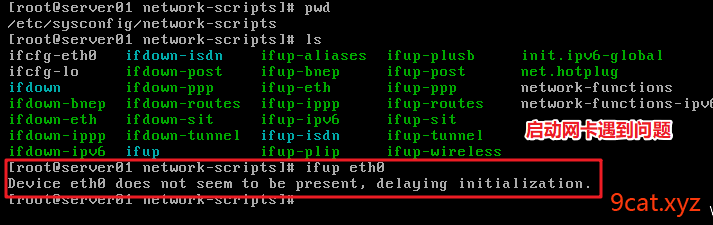
解决方案
配置这个文件


/etc/sysconfig/network-scripts/ifcfg-eth0
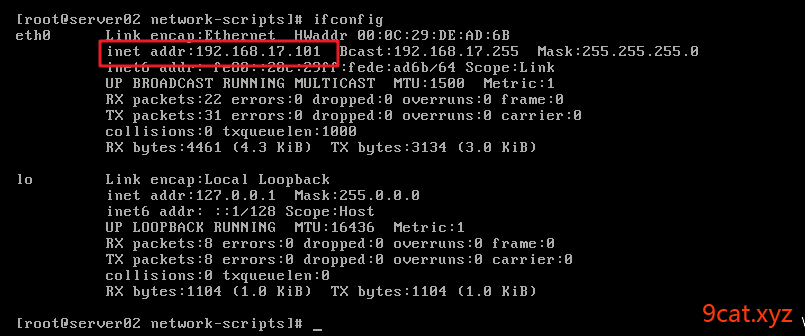
重启服务器
shell > reboot
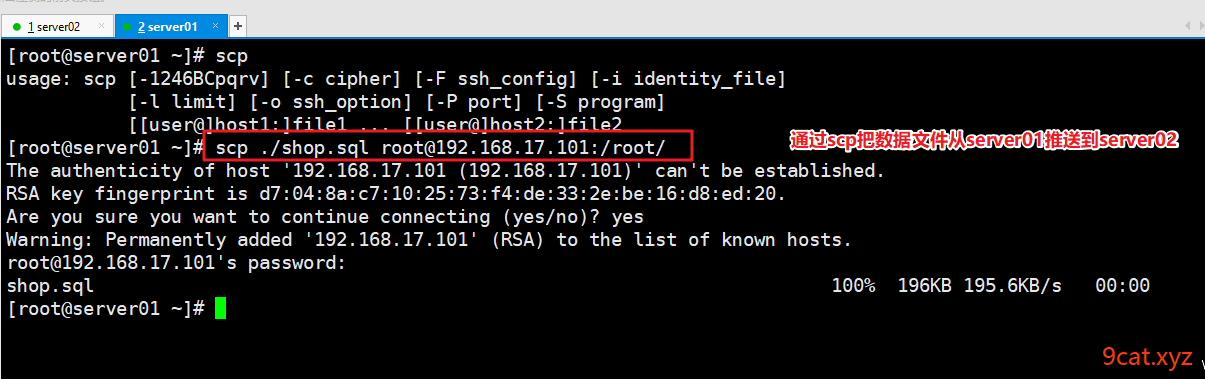
数据迁移
数据迁移步骤:
①源数据库服务器导出数据

②导入数据到新数据库服务器
数据备份文件获取
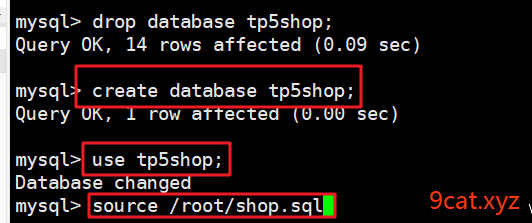
业务代码配置连接数据库
mysql数据库迁移到其他服务器,WEB服务器里的mysql应该停止了,业务代码也需要切换到新的单点mysql数据库服务器了
①停止到server01 web服务器的mysql服务
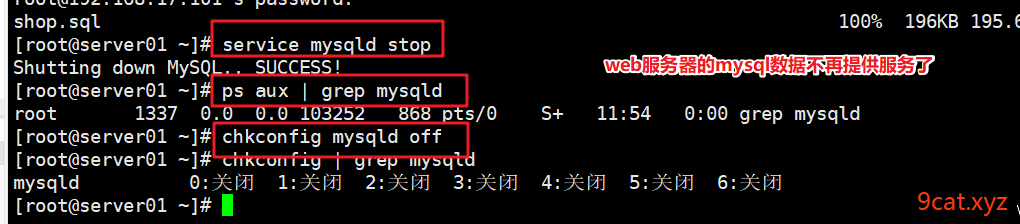
②业务代码连接数据库配置到新的数据库服务器

问题:
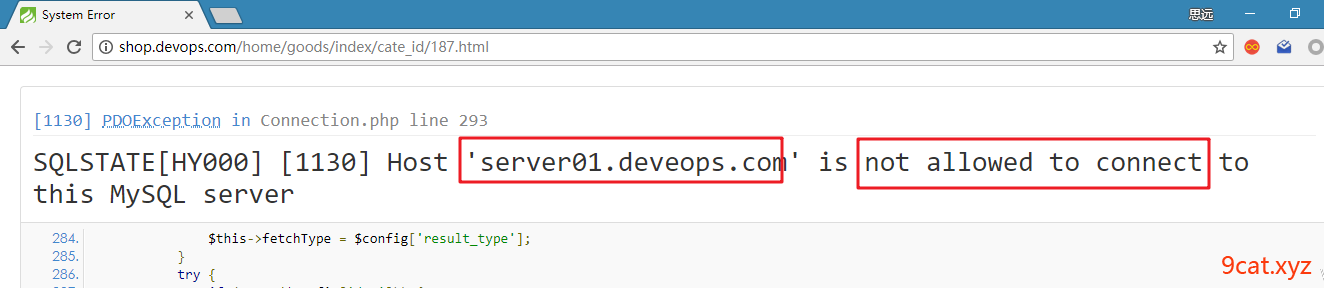
mysql默认不允许远程登录,mysql.user表里有个Host字段,可以进行控制,需要改为%[任意匹配]
解决方案:
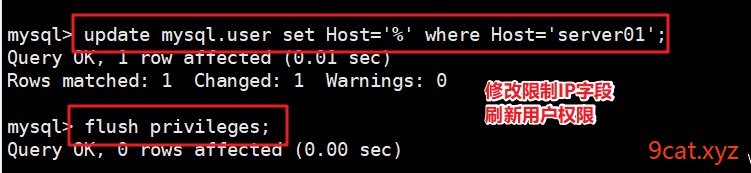
Tip:mysql host限制和套接字连接

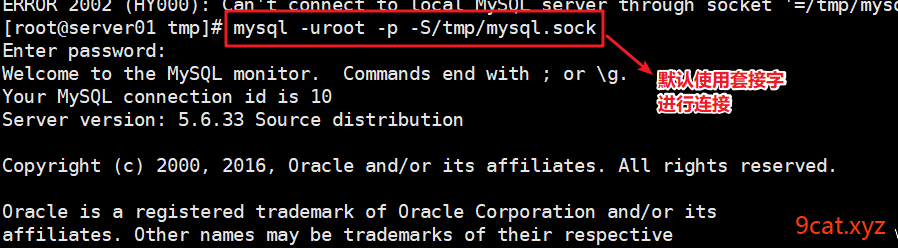
MySQL相关命令
CURD 它代表创建(Create)、更新(Update)、读取(Retrieve)和删除(Delete)操作
数据库操作流程:database(数据库)=>table(数据表)=>column(列[字段]
6.1、创建语句
列类型(字段)
数字类型:
整数类型 TINYINT SMALLINT MEDIUMINT INT BIGINT
浮点数类型 FLOAT DOUBLE
定点数类型 DECIMAL
位类型 BIT
文本类型:
CHAR系列 CHAR VARCHAR
TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
BLOB(binary large object) 系列
TINYBLOB BLOB MEDIUMBLOB LONGBLOB
BINARY系列 BINARY VARBINARY
枚举类型: ENUM [单选]
集合类型: SET [多选,复选]
时间和日期类型: DATE TIME DATETIME(Y-M-D H:i:s) TIMESTAMP YEAR
存储引擎:
汽车引擎 起速快 跑的也快 拉不太重的东西
拖拉机引擎 起速慢 跑的也慢 拉的东西可以拉很重
物理小知识:做功的方式不同,轮胎不一样
mysql中的存储引擎,也是一样,不同的存储引擎,数据的存储方式和功能都不同,合理选择对应的存储引擎,是数据库设计和优化中,重要的部分。
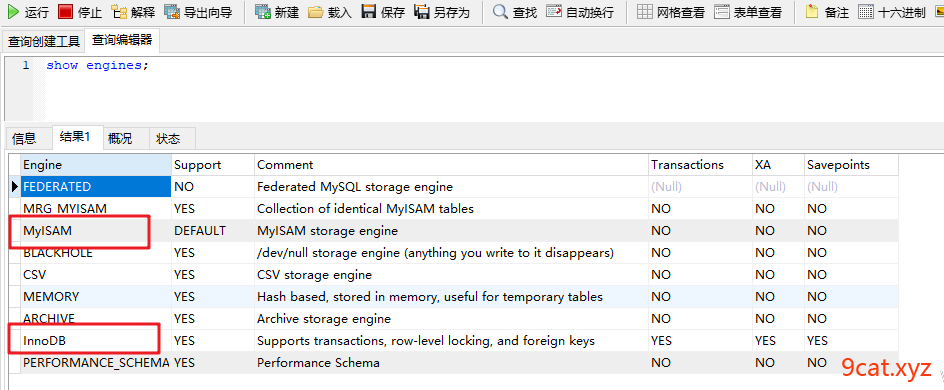
常用的
MyISAM 一般的是默认的
InnoDB 并发写入更好一些,可以进行行级别锁
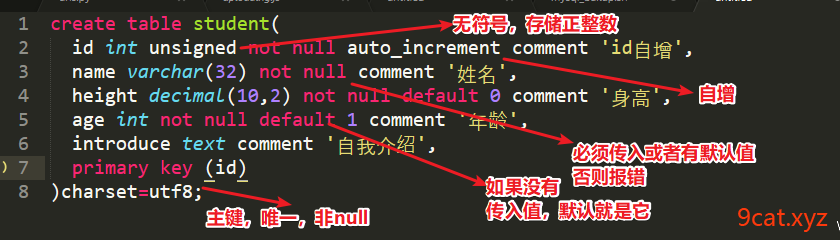
创建一个表
6.2、插入语句
语法:
insert into tablename values (xx,xx,xx);

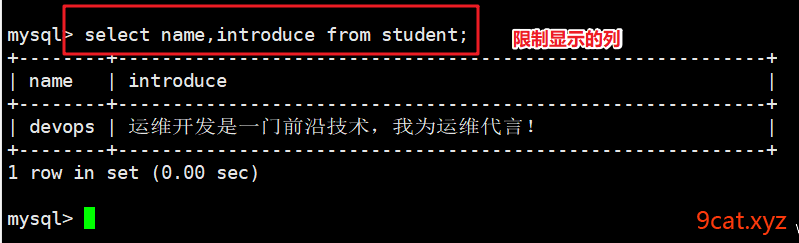
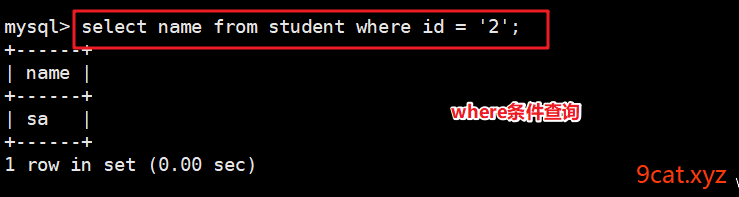
6.3、查询语句
语法:
select 查询显示的列 from 表名称 [where][limit][order by];

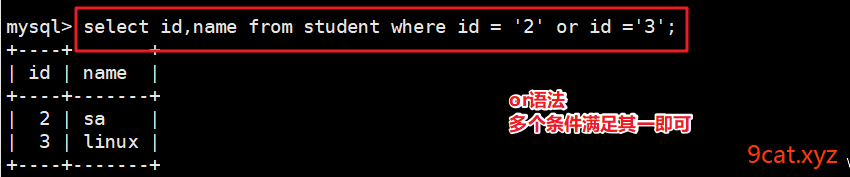
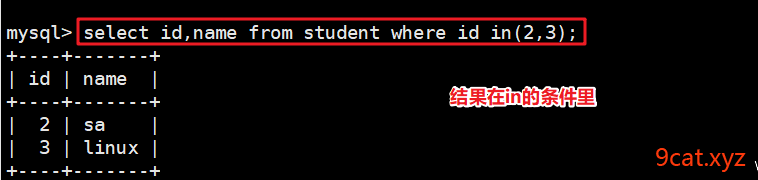
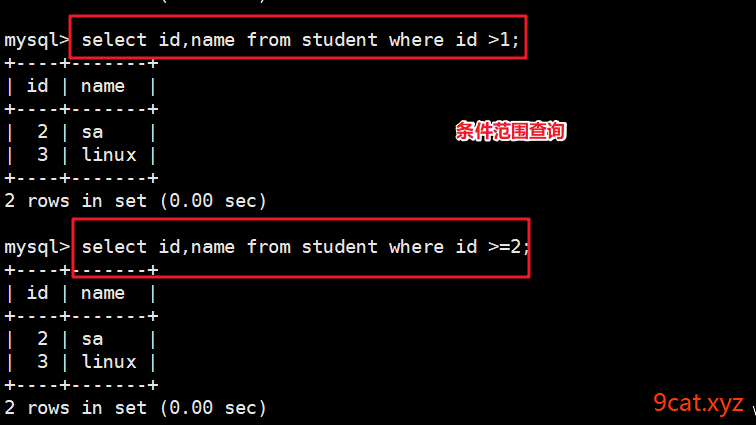


like查询模糊查询
like introduce ‘%服务器%’

6.4、修改语句
语法:
update 表名称 set 表字段 [where] 查询条件;
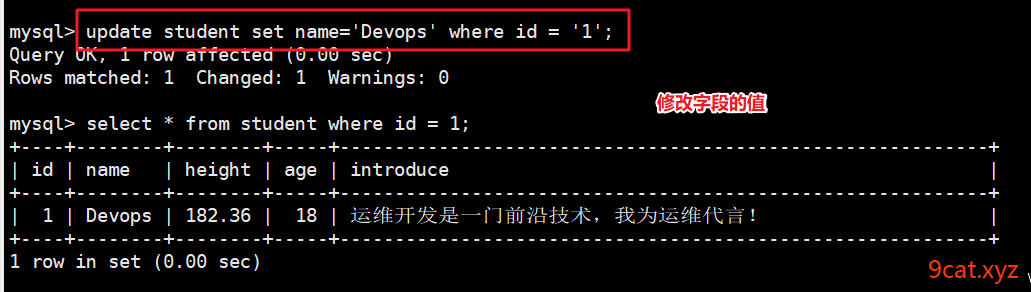
6.5、删除语句
基本上实际业务环境下不会使用
语法:
delete from 表名称 [where] 查询条件
不管是修改还是删除语句,最好在where条件判断之后加上一个limit 1,这样即使条件出现的了错误,也只会影响一条。
6.6、系统信息
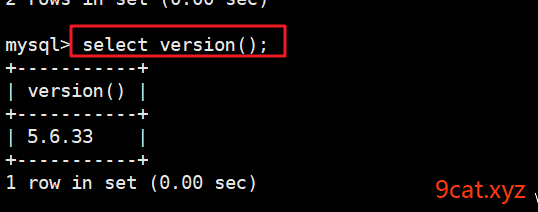
查看数据库版本
mysql > select version();
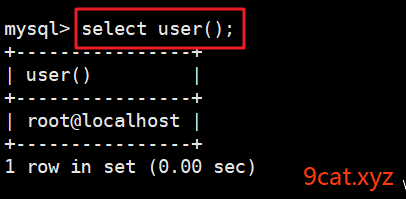
查看当前登录用户
mysql > select user();
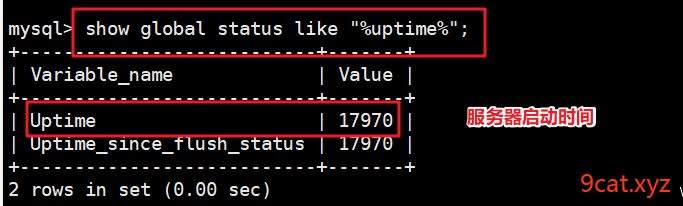
查看数据库运行时间
mysql > show global status like 'uptime';
查询数据库链接数
mysql > show processlist;

三、phpMyAdmin部署使用
1、介绍

phpmyadmin web端方式,管理mysql数据库的软件工具
要求:由php开发,需要服务器已经安装好PHP
官方网址:https://www.phpmyadmin.net/
client/s browser/s
上传到服务器
server02 MySQL服务器,把相关的工具在server02使用
上传软件包

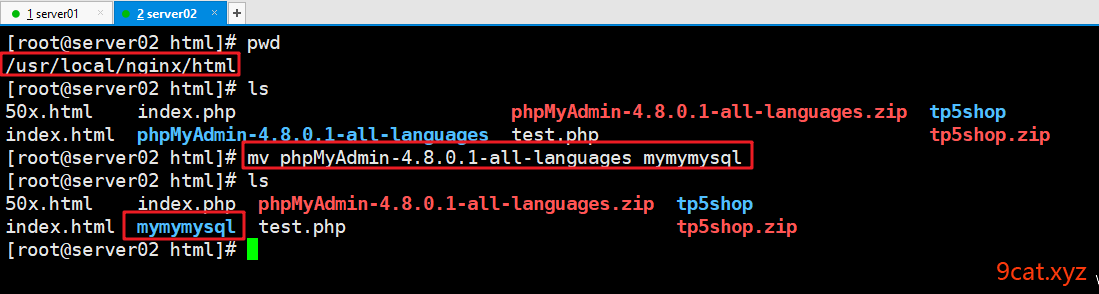
解压改名

修改名称路径最好不要直接修改为phpmyadmin,隐晦一点儿,让别人猜不到是什么。
mymymysql
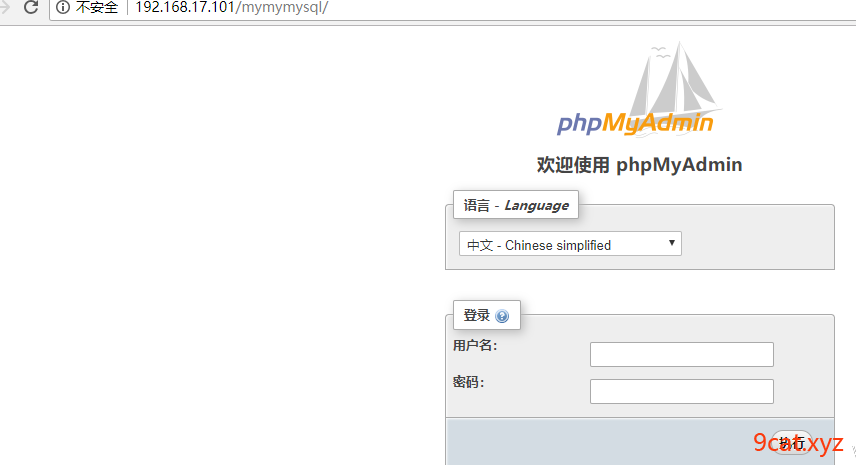
配置
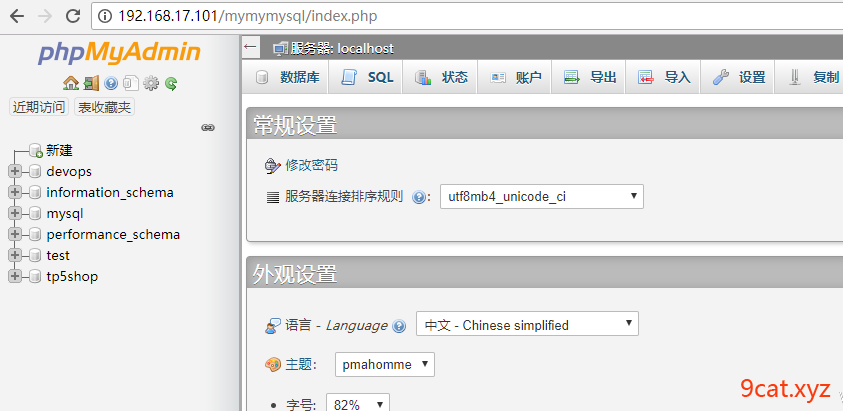
需要使用ip和目录方式访问
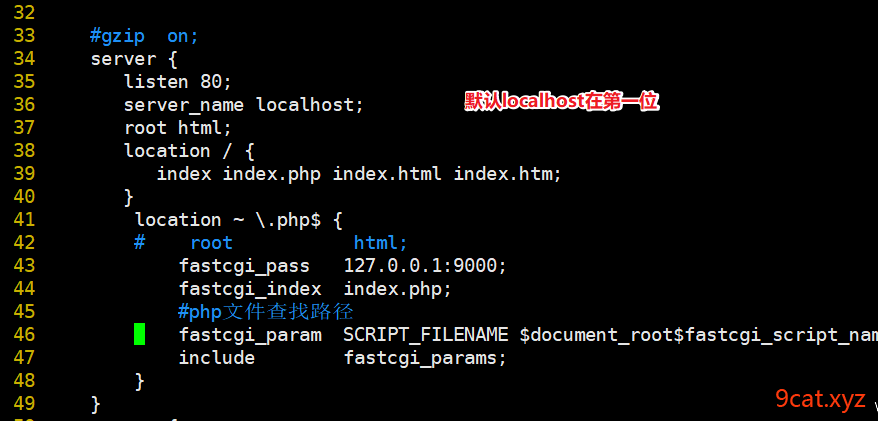
默认访问第一个虚拟机,localhost,目录在html下
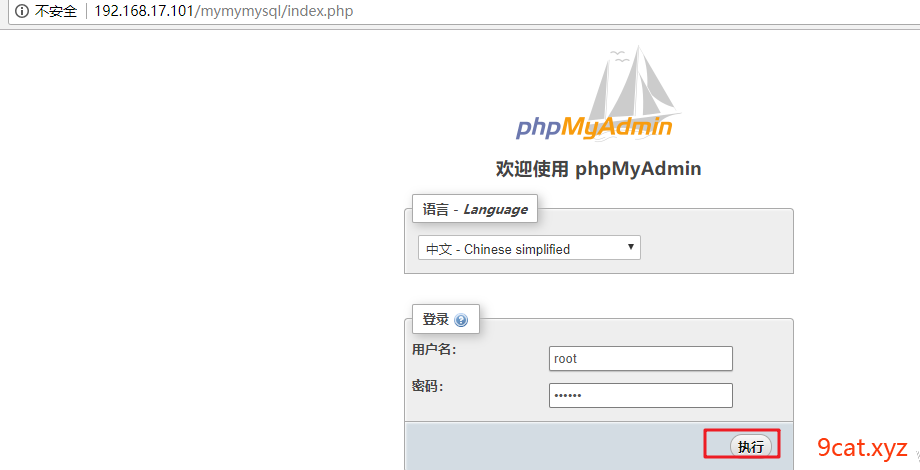
登录查看
也可以设置一个域名进行访问
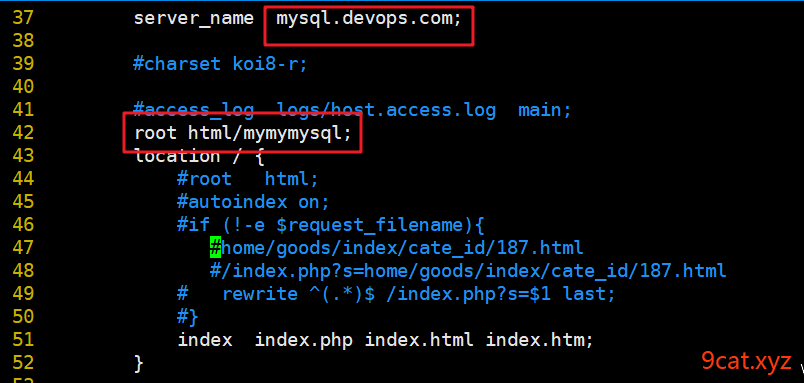
注意同时解析域名操作
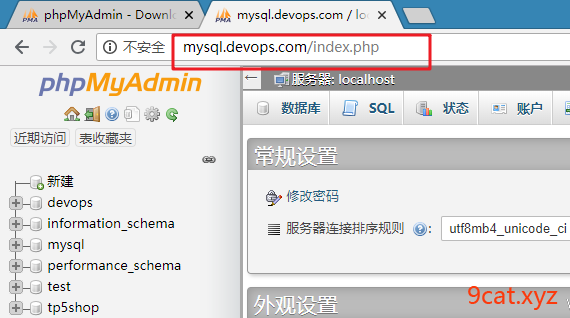
登录后操作管理平台
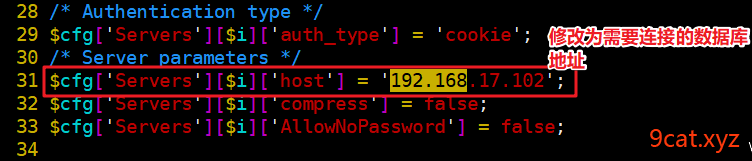
如果phpmyadmin的web服务器和mysql服务器不在同一上。就需要修改一下相关配置
①复制示列配置文件
shell > cd /usr/local/nginx/html/mymymysql
shell > cp config.sample.inc.php config.inc.php
②修改对应的host参数
更加详细的配置选项 具有所有的配置项
一般做法是,使用默认phpmyadmin根目录下的config.inc.php最小化配置
如果需要的配置项没有存在于config.inc.php中,就从原始的配置文件phpmyadmin的网站根目录/libraries/config.default.php复制出来,进行修改。
简单使用
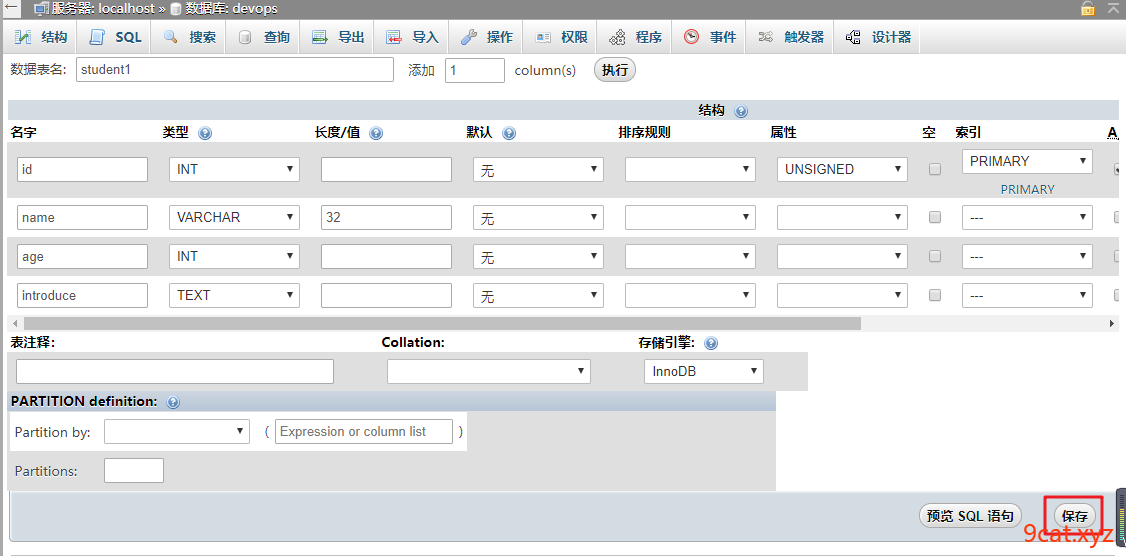
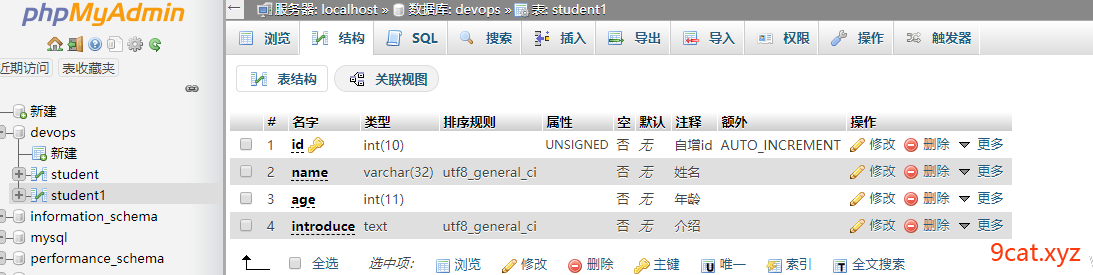
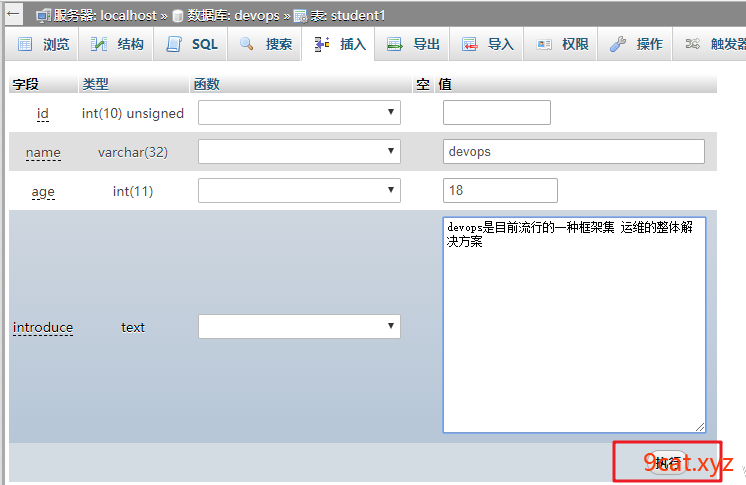
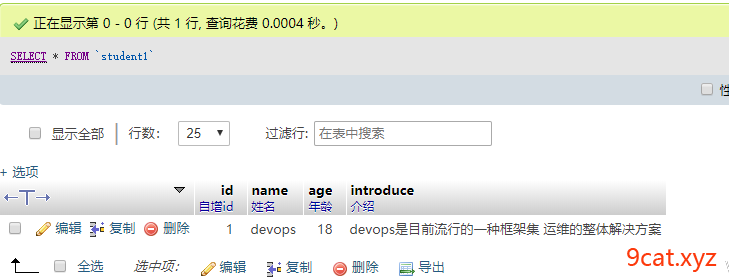
案例一:创建一个简单表
案例二:CURD操作
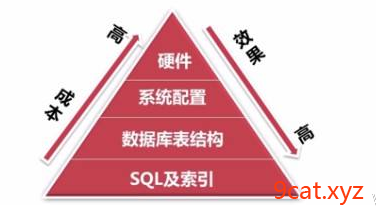
MySQL优化方向介绍(扩展)
DBA数据库管理员和开发一般需要掌握的
1、优化方向
问:如果出现数据访问变慢的情况,试提出解决方案或者优化方向,如何优化mysql?
①存储层 存储引擎 列类型选择 范式(三范式[约束规范])
②设计层 索引 缓存 分区表
③sql层 使用执行效率高的sql语句 explain 执行计划 慢查询日志记录
④架构层 分布式数据库架构 使用多台数据库服务器,解决数据库访问并发的问题
主从复制
课程进行到以上部分
2、索引
生活中实际索引的体现
书的目录 指引
公交站牌
办公室的指引牌



索引是一种数据结构(存储数据的方式),存储字段值的内容和对应真实数据的物理地址。
查询数据通过索引查询到物理地址,再通过物理地址直接定位数据。
索引是一种以空间换取时间的方式,牺牲了写的速度,提高查询速度。
案例:是否使用索引的区别
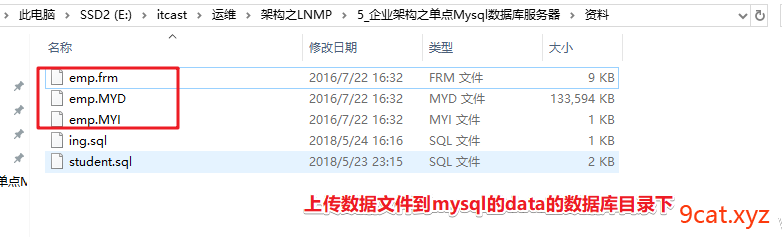
上传数据文件到数据目录下

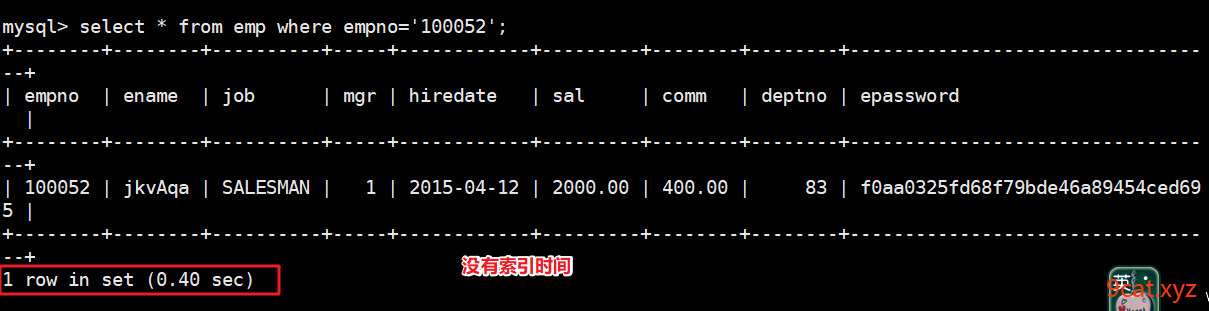
添加一个主键(默认主键索引)
mysql > alter table emp add primary key(empno);

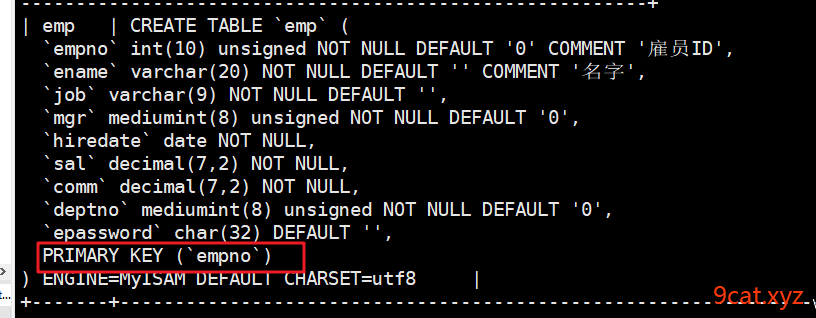
增加之后测试查询返回时间
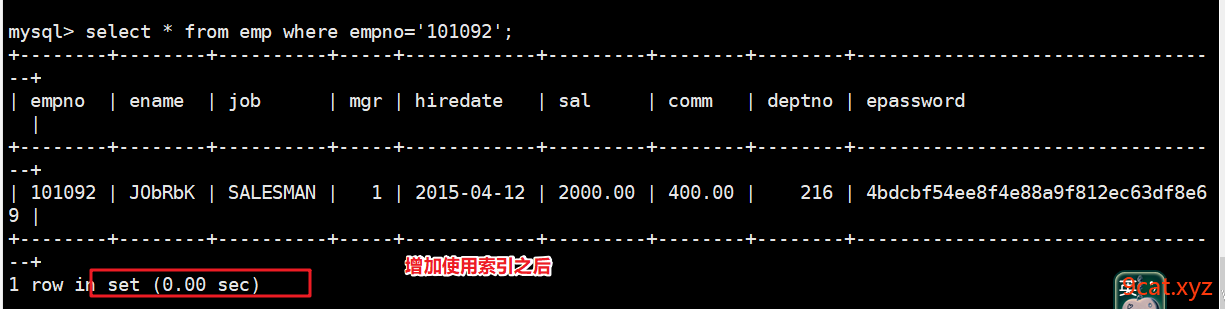
索引的类型:
mysql中使用关键字 key index 标识索引
主键索引 primary key 主键约束 唯一性 不能为null
唯一索引 unique key 唯一约束 唯一性 可以为null
普通索引 key
全文索引 fulltext key 只支持文本类型(char varchar text),文本中的内容进行分词,分别建立索引 mysql5.6以下是innodb不支持 官方全文索引不使用,使用第三方工具
sphinx(搜索分词)、xunsearch(讯搜)、luncene(分词索引)、solr、elasticsearch
特殊索引类型:
复合(联合)索引 多个字段共同组成一个索引 查询条件有多个时,可以使用到
前缀索引
创建索引的方式:
①建立表结构设计索引
create table 表名(
字段~~~~~~~~~
primary key (id),
unique index 名字,
index 名字(字段),
index 名字(字段,字段), --复合索引
fulltext index 名字(字段);
)
②使用修改结构语法的语句(alter table)
alter table 表名
add primary key (id),
add unique key名字(字段),
add key|index 名字(字段),
add key 名字(字段,字段), --复合索引
add fulltext key 名字(字段);
创建索引
增加一个普通索引和复合索引
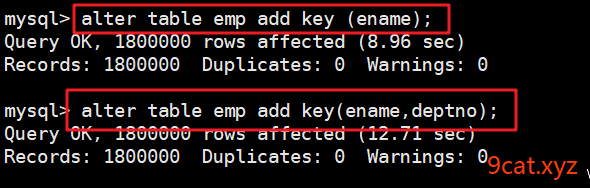
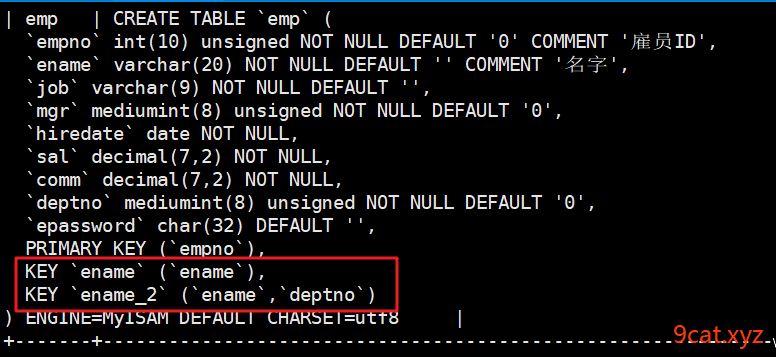
删除索引
alter table 表名称 drop key索引名称
主键 alter table 表名称 drop primary key

缓存
缓存:
获取数据经过sql解析等一系列操作才可以获取,如果查询时间较长,每次都从头开始解析执行获取,很浪费时间。
本次查询完毕,如果数据没有改变,就没有必要重新再查一次。把之前查询后的结果,存储起来,这个结果就是一个缓存。
需要经过一系列操作得到的结果存储起来,之后得到结果直接返回。
①查看并开启缓存
临时生效
mysql > show variables like 'query_cache%';
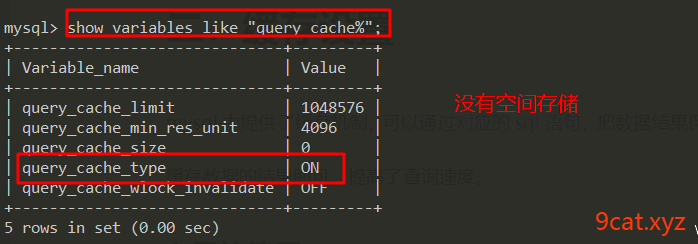
mysql > set global query_cache_size=64*1024*1024;
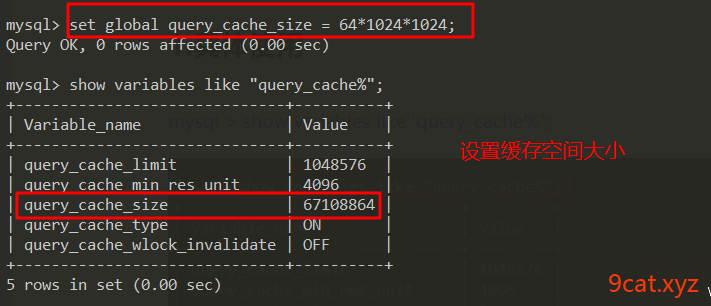
永久生效
vim /etc/my.cnf
[mysqld]中添加:
query_cache_size = 64M
query_cache_type = ON
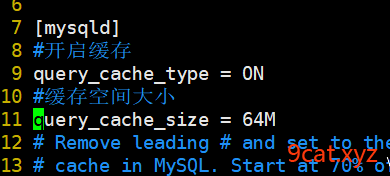
修改配置文件之后,需要重启mysqld服务
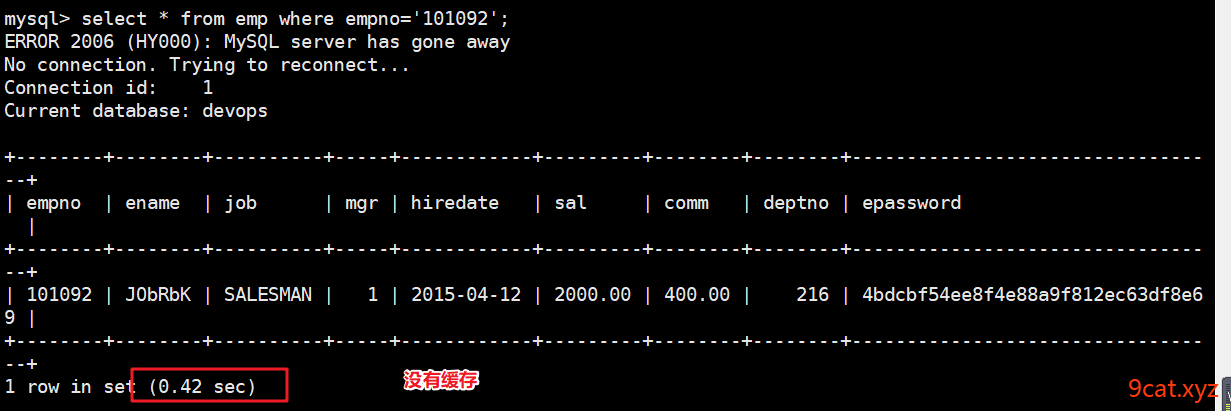
②测试缓存后的查询效果

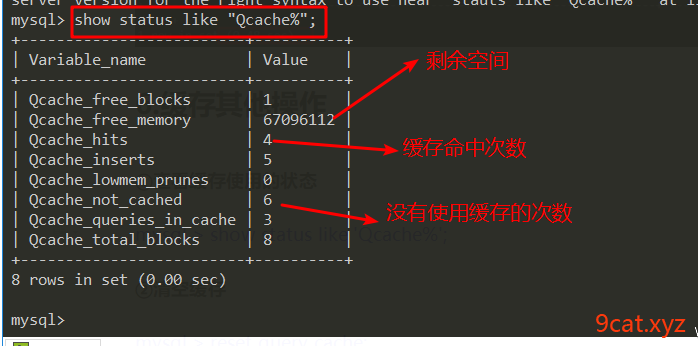
③查看缓存使用的状态
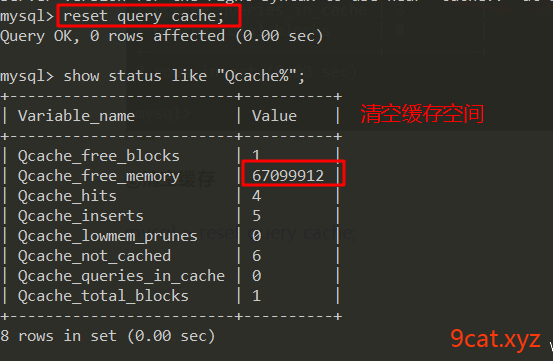
mysql > show status like 'Qcache%';
④清空缓存
mysql > reset query cache;
注意:
①如果sql语句不想使用缓存在语句前加入sql_no_cache
②如果数据表发生了改变,缓存失效
③SQL区别大小写 会被认为是不同sql
④SQL中如果有随机的函数,缓存使用不到
SQL语句
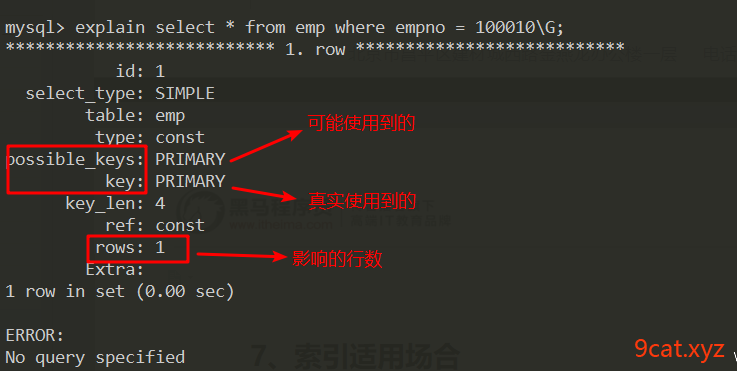
建立索引是为了能够提高查询效率。检查索引是否使用到。
explain执行计划,不会真实执行,分析sql语句执行的过程和使用的资源。
别名语法desc
语法:desc|explain 执行的sql语句 \G;
分库、分表
如果数据表数量在千万级别,通过增加索引和缓存,就可以达到很不错的效果了。
当数据表单表亿级别,通过把表拆分进行存储,分表操作。
分库:一个业务分配一库
分区、分表类型:
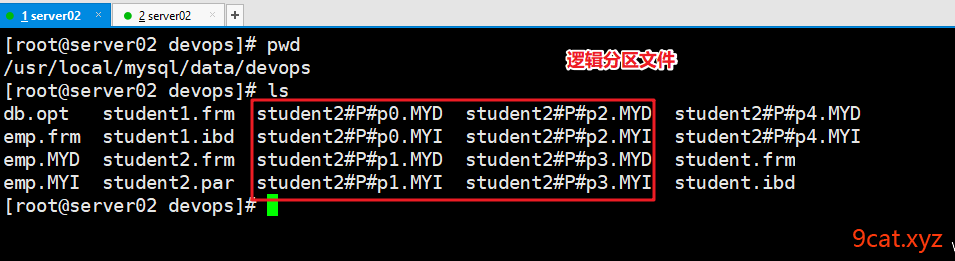
①逻辑分区 分表 真实还是一个表 逻辑分为多个 使用的sql语句和单表相同
key/hash range/list
②物理分表 把数据分配到几个真实数据表中,sql语句需要确定操作哪个表
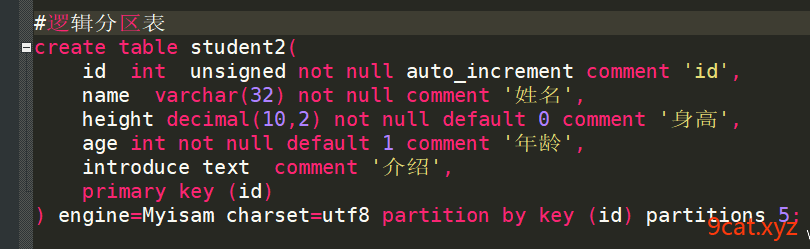
案列一:逻辑分区
语法:
create(
字段 类型
……
)
partition by key (字段) partitions 分区数目
案列二:物理分表 (水平分表)
案列三:物理分表(垂直分表)
user表
id username password sex hobby cardid
需求:如果进行用户登录操作,需要查询id username password
解决方案:把user表通过常用的字段和不太常用的字段,分割为两个表
user表
id username password
user_ext表
id sex hobby cardid user_id