大型网站核心优化之mysql一
Mysql核心优化
https://www.zhihu.com/question/19719997
分析问题
浏览器=>web服务器=>后端脚本(php)=>数据库(mysql)
①提高并发量 负载均衡(分布式服务器架构) 并发量更高的软件(nginx)
②页面静态化 静态页面缓存(反向代理服务器) 不经常发生数据变动的动态网页生成为静态网页,提高访问速度
③内存缓存优化 把数据缓存到内存中,提高数据响应速度
④数据库优化
一般数据读写频繁,可以缓存到内存中。但是内存容量有限,不能够把大量数据缓存,所以优化数据库软件本身是很有必要的
访问的环节越多,出现问题的几率越大。可能响应时间越慢
网站优化的两种方式:
①减少访问环节步骤
②提高每一个环节步骤的返回速度
优化方向
问:如果出现数据访问变慢的情况,试提出解决方案或者优化方向,如何优化mysql?
①存储层 存储引擎 列类型选择 范式(三范式)
②设计层 索引 缓存 分区表(数据分开存储到不同的表中)
③sql层 使用执行效率高的sql语句 explain 执行计划 慢查询日志记录
④架构层 分布式数据库架构 使用多台数据库服务器,解决数据库访问并发的问题
主从复制 一主多从 从服务器复制主服务器数据 读写分离 写主读从
存储引擎
①创建一个数据库
查看mysql里的存储引擎
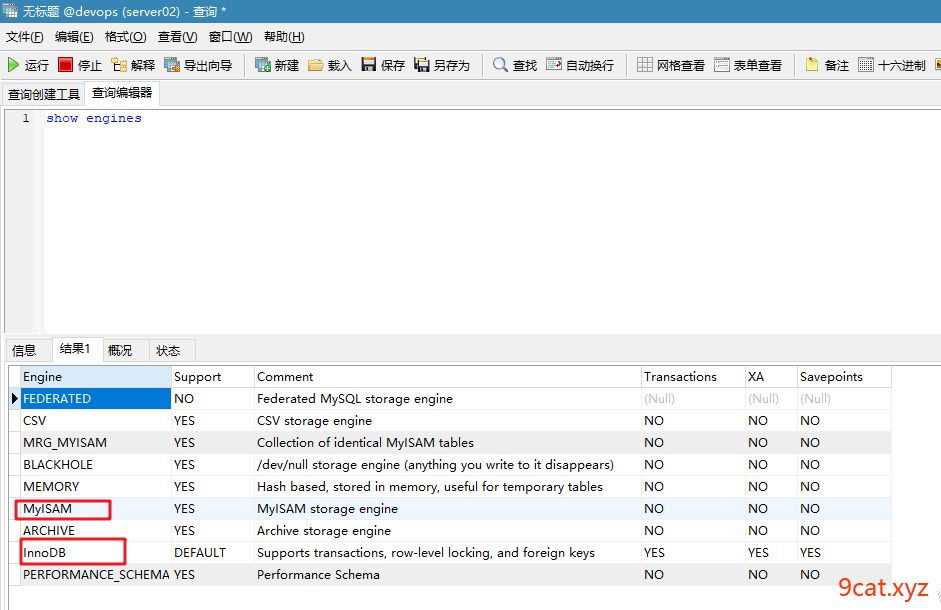
myisam
使用之前创建的数据库,或者新建一个数据库
①创建一个myisam的数据表
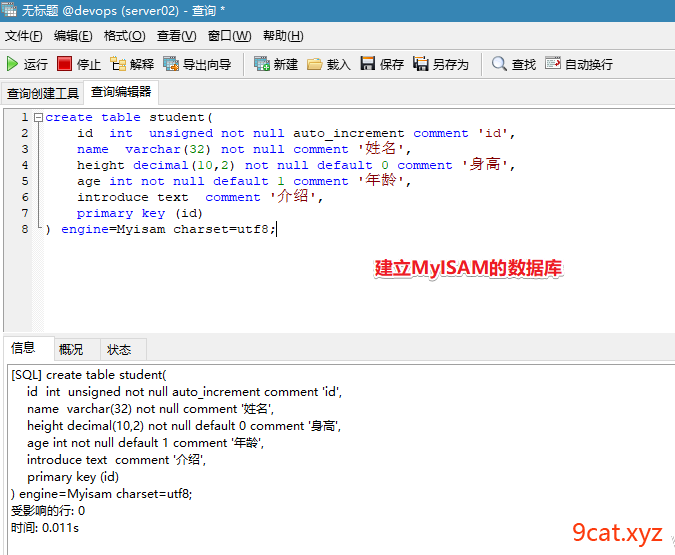
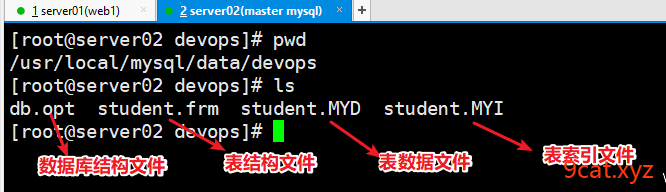
结构、数据、索引的物理文件
.frm 结构文件 .MYD 数据文件 .MYI 索引文件
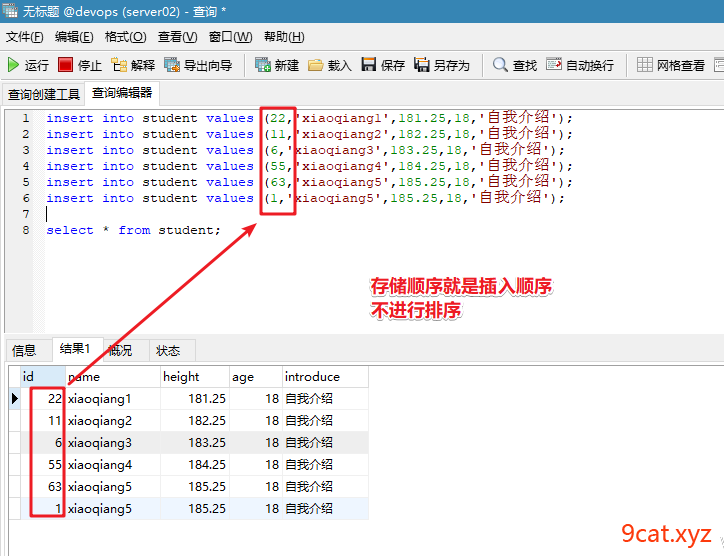
数据存储顺序
功能:复制备份、压缩机制
数据表生成文件有三个,如果进行数据备份和恢复,直接复制粘贴三个文件恢复即可。
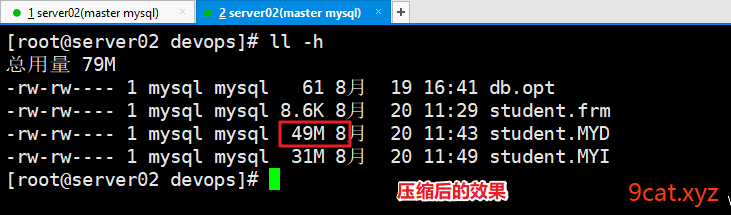
压缩机制:数据表进行压缩,节省存储空间,提高查询速度
语法:
cmd > myisampack tablename路径 压缩
cmd > myisamchk --unpack tablename路径 解压
cmd > myisamchk –rq tablename路径 重新生成索引
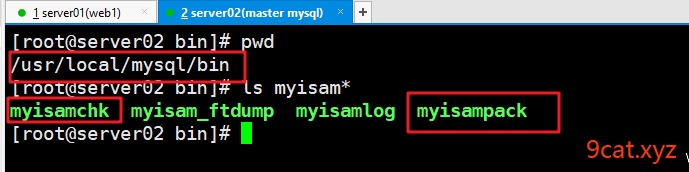
①复制数据生成多数据
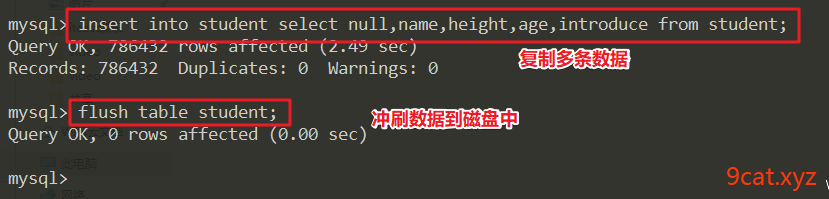
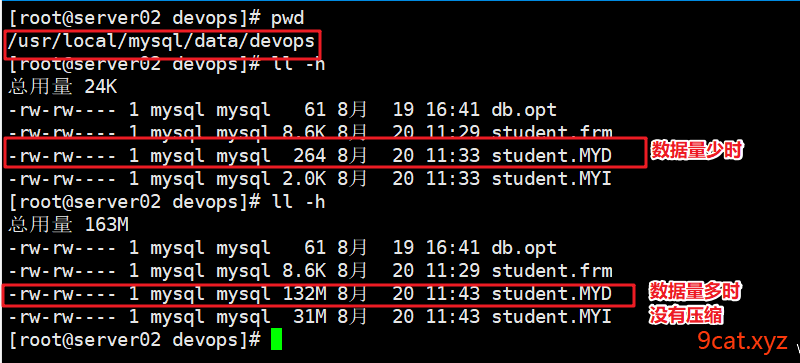
②压缩表文件,并重建索引
压缩
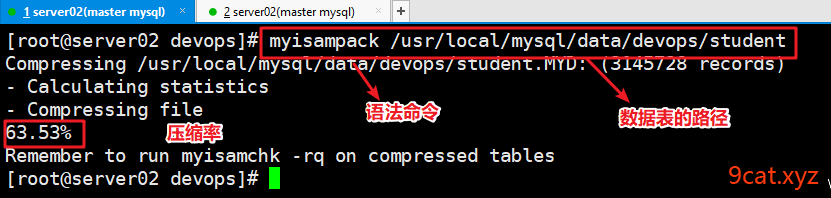
重建索引

压缩后的效果
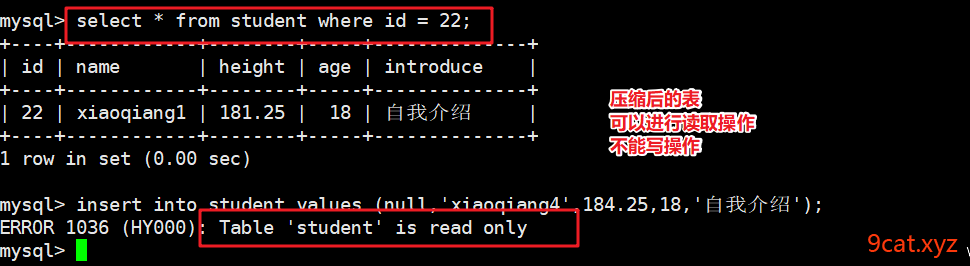
③测试表使用
④解压缩
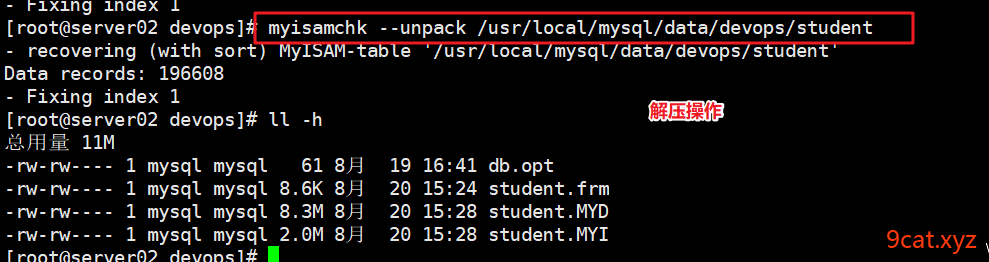
解压缩时,会自动重建索引,所以不需要手动创建了
myisam的压缩表操作,适合数据表不发生变动,但是数据量又比较大的情况。
主要进行读操作。历史资料
并发性:表级锁(并发写入)
myisam如果进行并发写入时,为了保证数据的一致性,加锁,只能使用表锁。锁表会影响到整个数据表的操作。并发性稍微逊色。
innodb
①创建innodb表
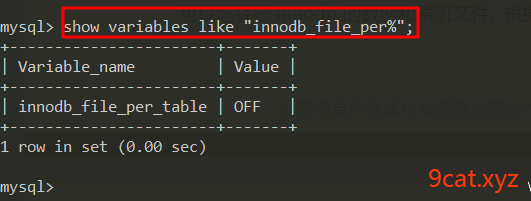
管理innodb表的数据,和整个mysql服务器的数据表为innodb的数据格式,是否分离开
mysql > show variables like 'innodb_file_per_table';
开启
mysql > set global innodb_file_per_table=1;
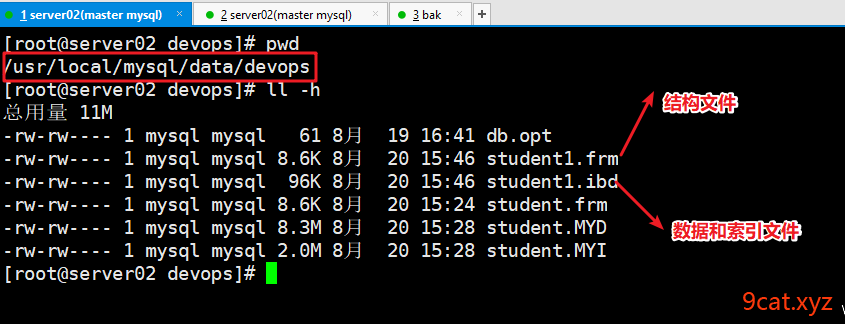
结构、数据、索引的物理文件
.frm 结构文件 .ibd 数据和索引文件
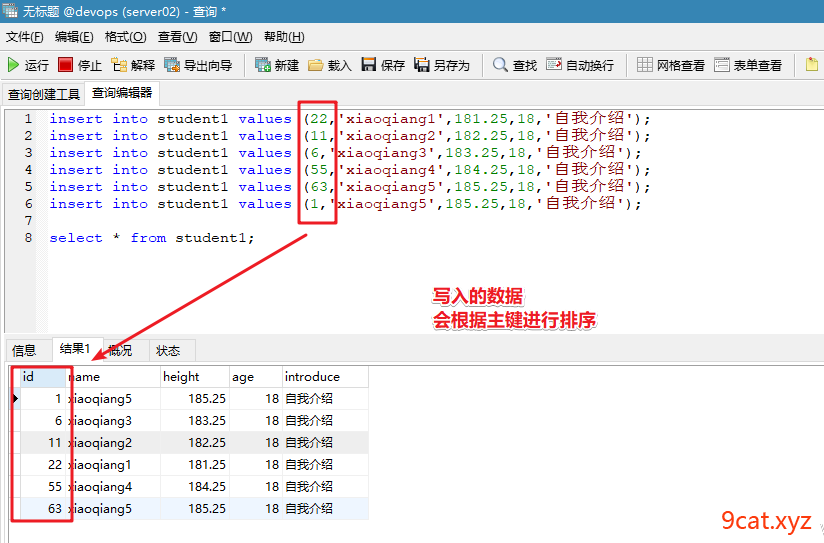
数据主键顺序存储
功能:事务、外键
innodb表不能够直接复制粘贴,备份恢复,需要导出sql文件,再导入恢复。
事务:保证数据的一致性,原子性 。
如果有多个业务操作,需要把所有操作都执行成功才可以。如果有不成功,则所有操作都不能够执行成功,把已经执行的操作进行回滚(rollback)。
A给B转100元。
①A扣100元 ②B加100元
问题:①执行成功了,但是②没有执行成功。
如果②不成功,那么①也应该不成功。需要把①进行回滚(rollback)。
外键:是一种约束,规则
主表 主键id
副表 id
主表id和副表classid进行关联,设定一个取值范围。
需求:
student表
id name classid
1 xiaoming 1
2 xiaohong 2
3 xiaoqiang 4
4 xiaohua 8
class表
id classname
1 php
2 html
3 java
4 linux
并发性:擅长并发
innodb在进行并发操作时,为了数据的一致性,可以使用行锁机制(锁表粒度)。影响数据只为当前行。并发性较好一些。
如何选择myisam和innodb
根据存储引擎的功能和特点进行选择。
①一般使用 普通读写较多的 备份恢复方便 压缩机制 myisam
cms(内容管理系统,快速搭建网站) myisam
②并发写入(行锁)事务 外键 innodb
订单系统(并发) innodb
4、其他存储引擎
1)Memory
数据置于内存的存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在Mysql重新启动时丢失。不支持text类型。
①创建一个测试student3表
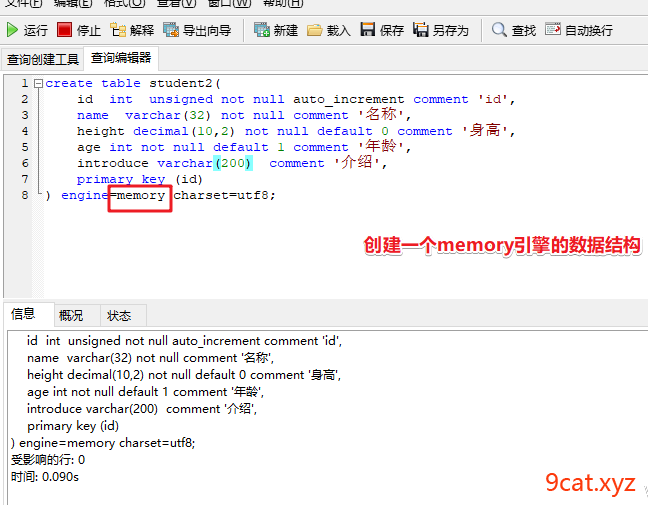
②测试使用
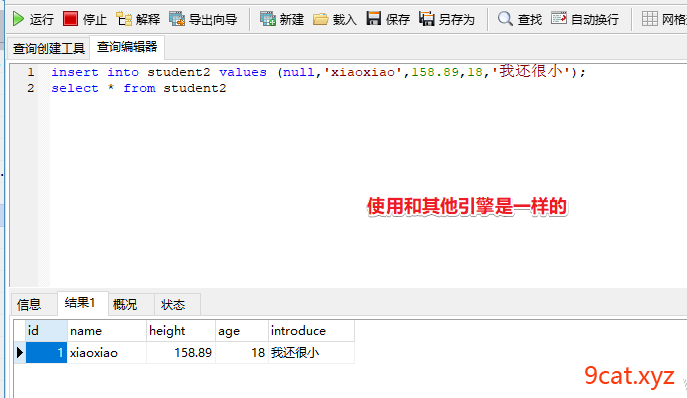
Archive
归档存储引擎,只支持数据的查询和写入。
经常用于存储日志等相关信息。
列类型选择
整数 int
字符串 文本类型 char varchar text
选取占据空间小的字段
占用小,数据查询遍历就会快速。
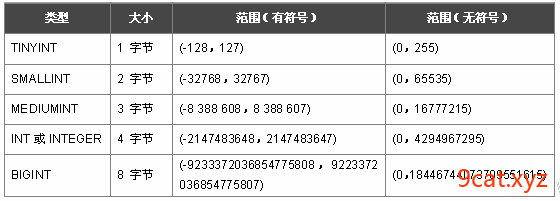
人类的年龄 200以内 tinyint
乌龟的年龄 smallint
如果表数据不会超过千万 mediumint
内容长度固定字段
char 定长 255字符 如果存储不满,以null补齐 分了100空间 字符占用85个,实际还是占用100(其中15个以null补齐)
varchar 变长 65535字节 如果使用utf-8的编码 3个字节一个字符,可以存储最大的字符数65535/3-1个字符 使用1个字符保存长度
电话号码 固定11位 char
邮箱地址 123456\@qq.com jiowoo12236\@163.com varchar
如果数据不定长,使用varchar会更节省空间。
如果追求查询效率,就需要使用char
整型存储
尽量使用能够整型存储数据
时间戳使用
使用int类型存储,节省空间,时间范围更好计算确定。
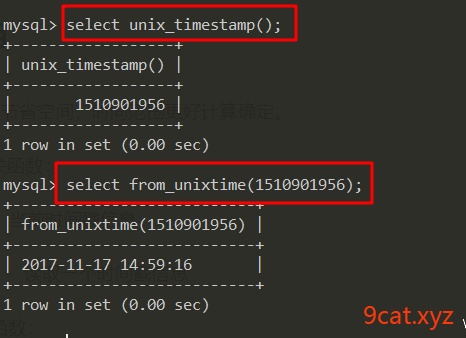
mysql中时间戳相关函数:
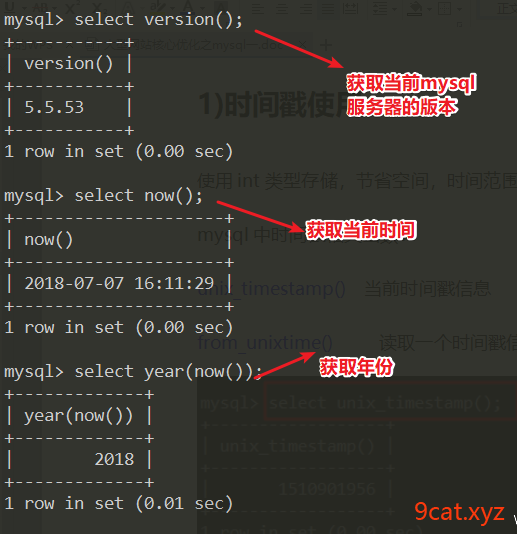
unix_timestamp() 当前时间戳信息
from_unixtime() 读取一个时间戳信息
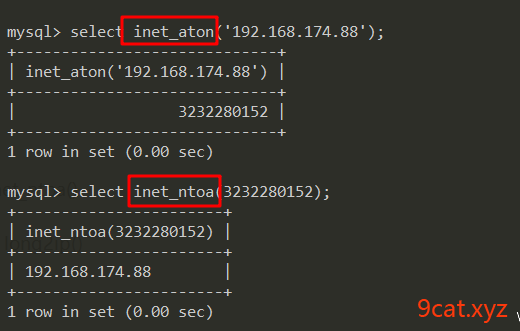
ip存储使用
ip转为int进行存储
A类 B类 C类
127.0.0.1
192.168.17.100
mysql: inet_aton() inet_ntoa()
四、范式
1、三范式
范式是一种规范或者约束。如果设计的数据库表是符合范式的,被认为是良好的数据设计。
第一范式 数据字段具有原子性,业务上不可再分割。
第二范式 数据具有唯一性(主键id)。
第三范式 数据字段和主键具有紧密联系,不允许出现冗余(rong[重复])字段
需求:存储学生信息
xiaoming 23岁了,计算机系的学生 ,男生
ER图
表设计:
| name | age | sex | department |
|---|---|---|---|
| xiaoming | 23 | 1 | 计算机 |
以上结构是符合第一范式。
| id | name | age | sex | department |
|---|---|---|---|---|
| 1 | xiaoming | 23 | 1 | 计算机 |
| 2 | xiaoming | 23 | 1 | 计算机 |
以上结构是符合第二范式。
| id | name | age | sex | department |
|---|---|---|---|---|
| 1 | xiaoming | 23 | 1 | 计算机 |
| 2 | xiaolv | 21 | 1 | 计算机 |
需要修改计算机系的名称。计算机科学与技术系
建立一个系别表
| id | departmentName | |||
|---|---|---|---|---|
| 1 | 计算机 | |||
| id | name | age | sex | departmenId |
| 1 | xiaoming | 23 | 1 | 1 |
| 2 | xiaolv | 21 | 1 | 1 |
以上结构是符合第三范式的。
1NF<2NF<3NF 一环一环满足的
逆(反)范式
真实业务的环境,为了能够实现更好的数据库表的性能,会选择不遵守范式的操作。
遵守第三范式,查询数据,需要连表操作,如果数据表数据很多,连表操作,会耗费大量时间。笛卡尔积(相乘 table1*table2)为了提高查询效率。可以选择把数据字段存储到同一个表中。
| id | name | age | sex | departmenId | departmentName |
|---|---|---|---|---|---|
| 1 | xiaoming | 23 | 1 | 1 | 计算机科学与技术 |
| 2 | xiaolv | 21 | 1 | 1 | 计算机科学与技术 |
建立了冗余(重复的)字段之后,一定要注意维护数据的一致性。
五、索引
1、什么是索引
生活中实际索引的体现
书的目录 指引
公交站牌
办公室的指引牌



索引是一种数据结构(存储数据的方式),存储字段值的内容和对应真实数据的物理地址。
查询数据通过索引查询到物理地址,再通过物理地址直接定位数据。
索引是一种以空间换取时间的方式,牺牲了写的速度,提高查询速度。
是否使用索引的差别
①复制恢复表
②建立主键索引
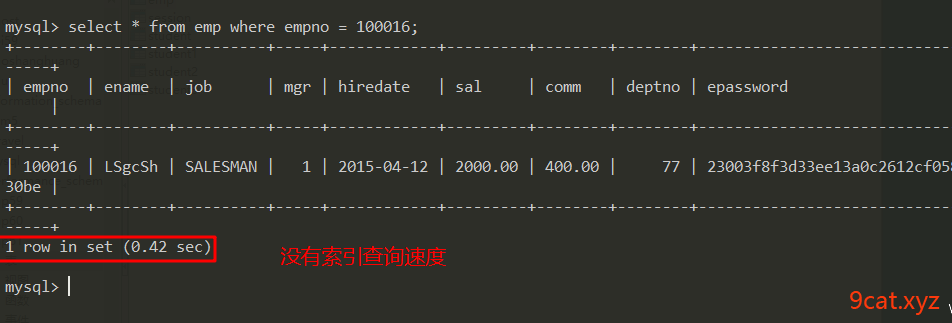
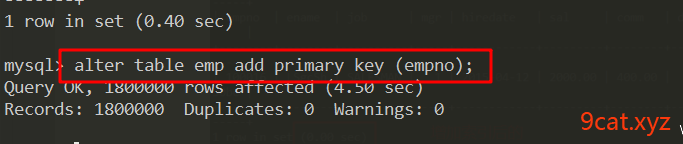
给emp表增加主键
mysql > alter table emp add primary key(empno);
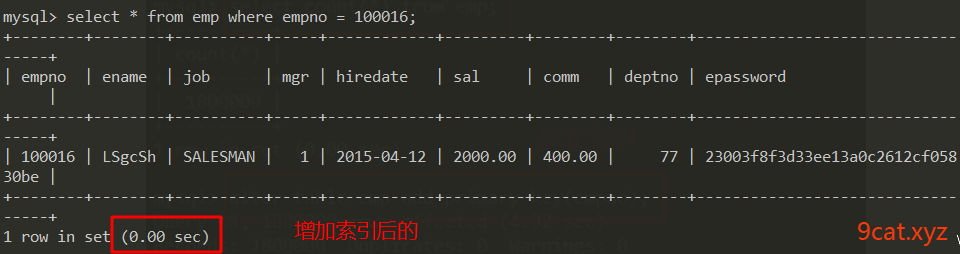
索引为什么速度快

之前查询数据需要遍历整个数据表
建立索引之后,查询变为:
查询字段=>索引=>物理地址=>真实数据
创建索引
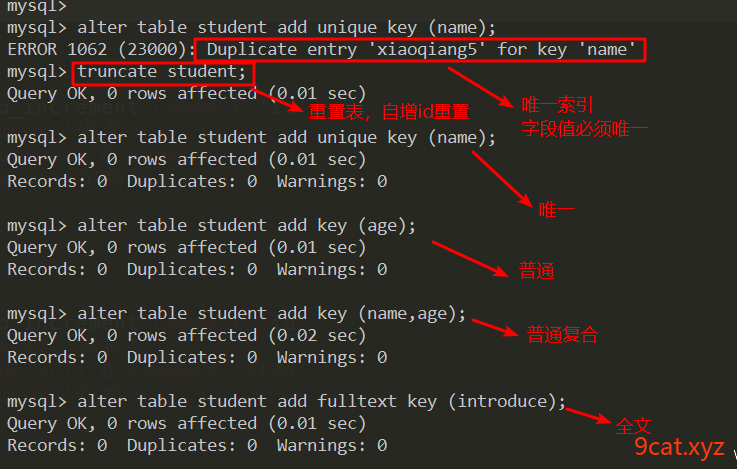
索引的类型:
mysql中使用关键字 key index 标识索引
主键索引 primary key 主键约束 唯一性 值不能为null
唯一索引 unique key 唯一约束 唯一性 值可以为null
普通索引 key
全文索引 fulltext key 只支持文本类型(char varchar text),文本中的内容进行分词,分别建立索引 mysql5.6以下是innodb不支持
特殊索引类型:
复合(联合)索引 多个字段共同组成一个索引 查询条件有多个时,可以使用到
前缀索引 选择可以标识字段唯一性的前一部分,建立索引
创建索引的方式:
①建立表结构设计索引
create table 表名(
字段~~~~~~~~~
primary key (id),
unique index 名字,
index 名字(字段),
index 名字(字段,字段), --复合索引
fulltext index 名字(字段);
)
②使用修改结构语法的语句(alter table)
alter table 表名
add primary key (id),
add unique key名字(字段),
add key|index 名字(字段),
add key 名字(字段,字段), --复合索引
add fulltext key 名字(字段);
如果不指定索引名称,会默认选择字段名称,是复合索引的话,选择第一个字段作为索引名称。如果索引名称有重复冲突,会自动顺延编号。
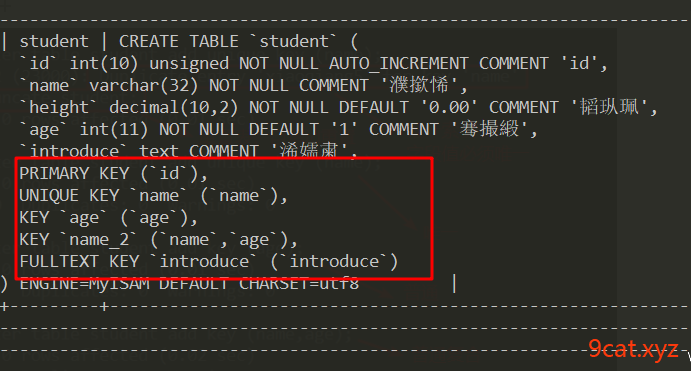
删除索引
alter table 表名称 drop 索引类型key 索引名称
①删除主键带自增属性的

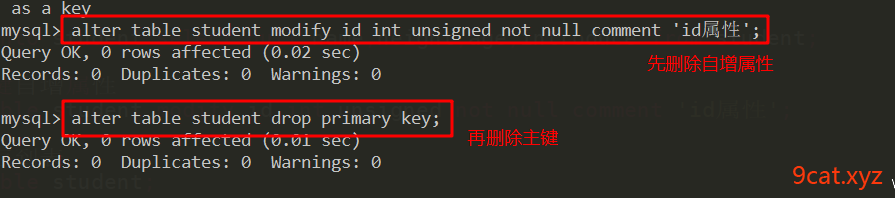
②删除非主键索引
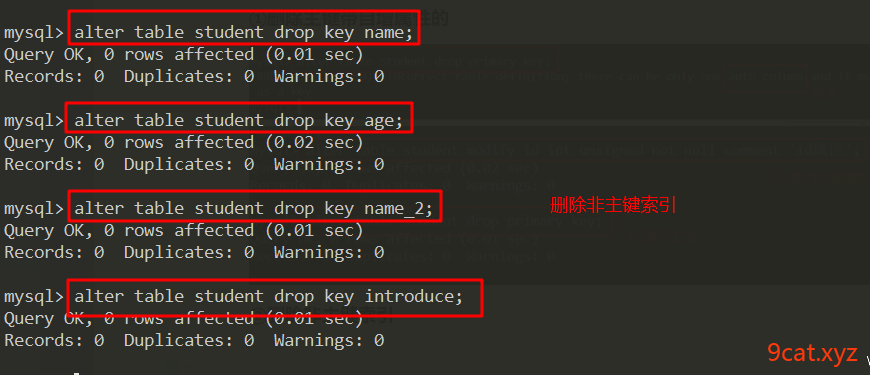
删除非主键索引使用key关键字,后面跟索引名称
执行计划explain
http://www.cnblogs.com/liujingyuan789/p/6061188.html
建立索引是为了能够提高查询效率。检查索引是否使用到。
explain执行计划,不会真实执行,分析sql语句执行的过程和使用的资源。
别名语法desc
语法:desc|explain 执行的sql语句 \G;
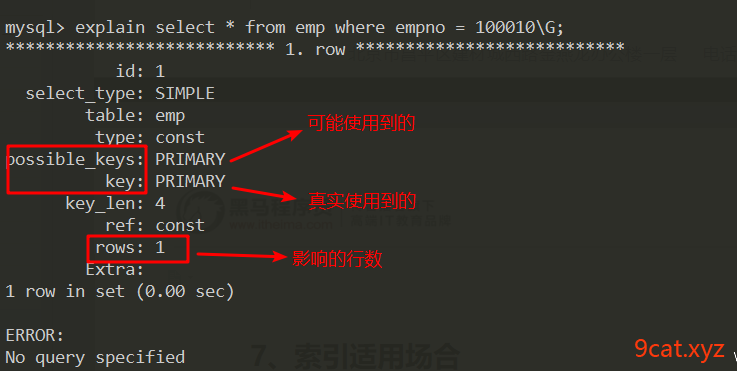
索引适用场合
在某些查询情况,建立索引能够查询效率,这些情况适合建立索引。
①where条件字段
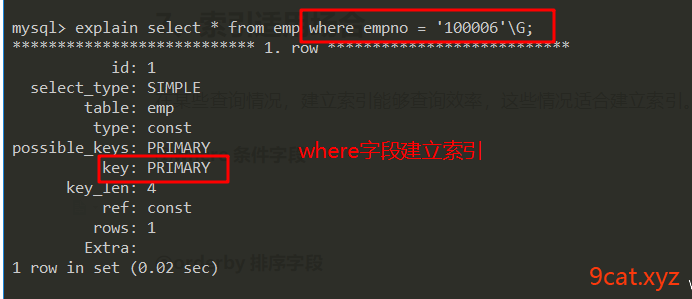
②orderby排序字段
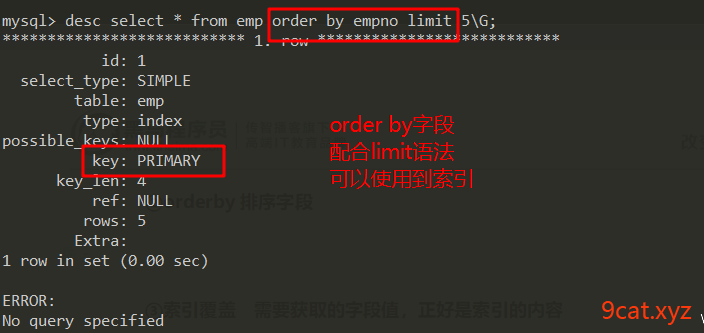
③索引覆盖 需要获取的字段值,正好是索引的内容
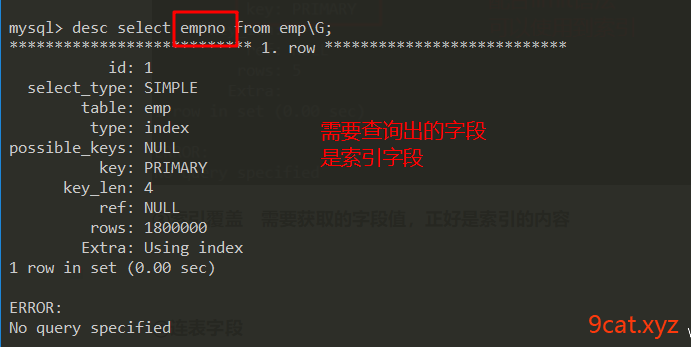
直接返回索引数据,不需要遍历数据表了
④连表字段
给连表的字段建立索引,可以使用到索引,提高查询速度。
on 语法之后的关键字段
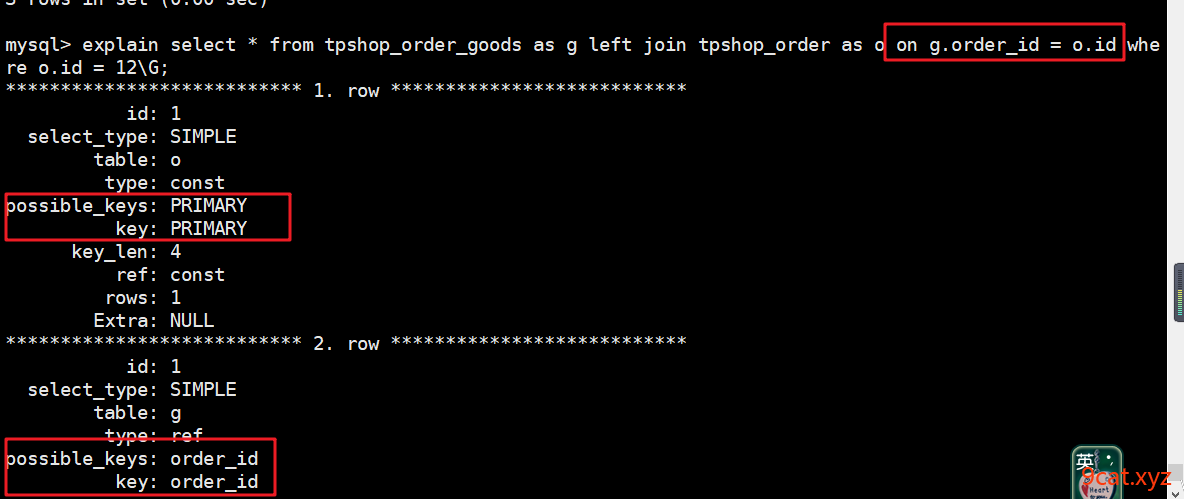
索引原则
建立的索引字段,可能没有使用到索引。原因是没有遵守索引的使用原则。
①列独立
字段类型不能够进行运算操作。
如果列类型不独立,就不能够使用到索引
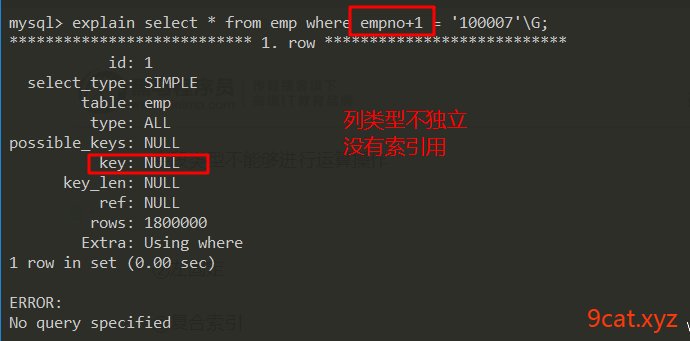
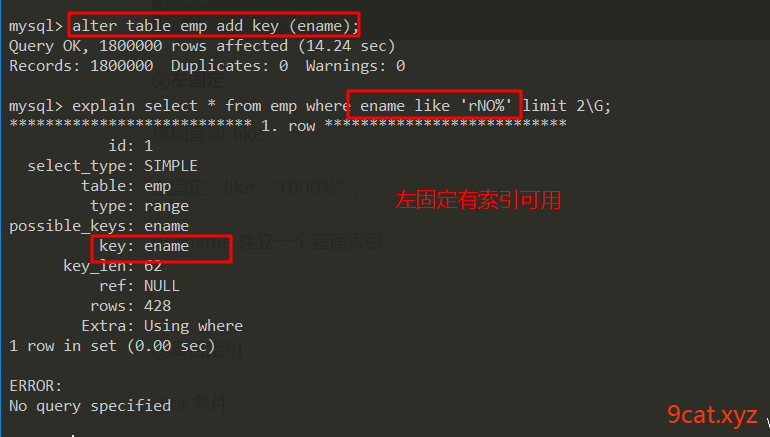
②左固定
模糊查询 like
左固定 like “1000%”;
给ename建立一个普通索引
③复合索引
需要同时出现在条件中,才可以使用到复合索引,单独使用不到
给ename和deptno建立复合索引

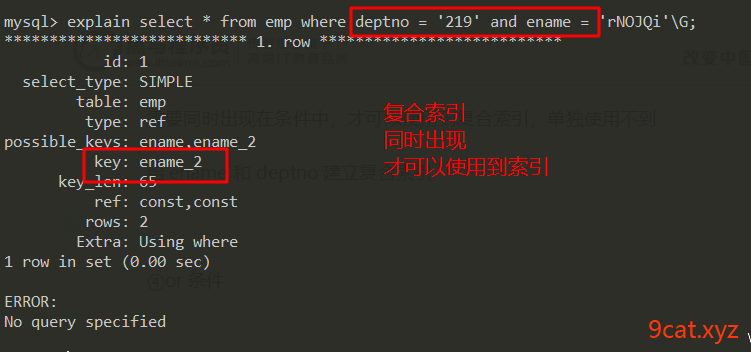
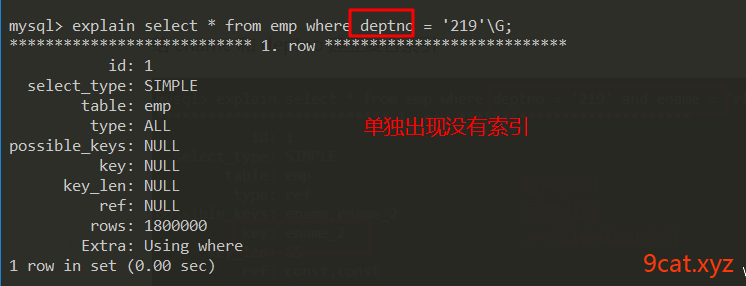
复合索引是遵循左原则的
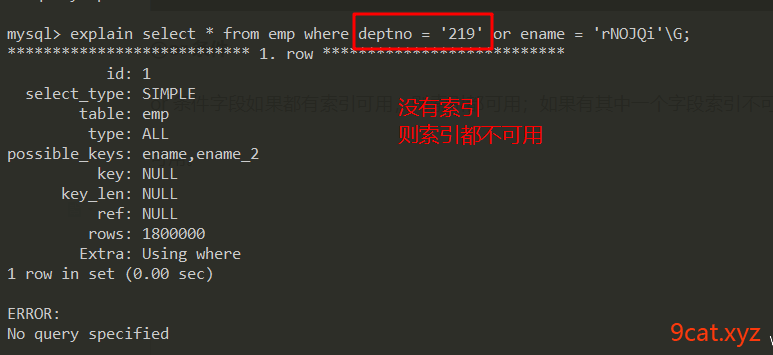
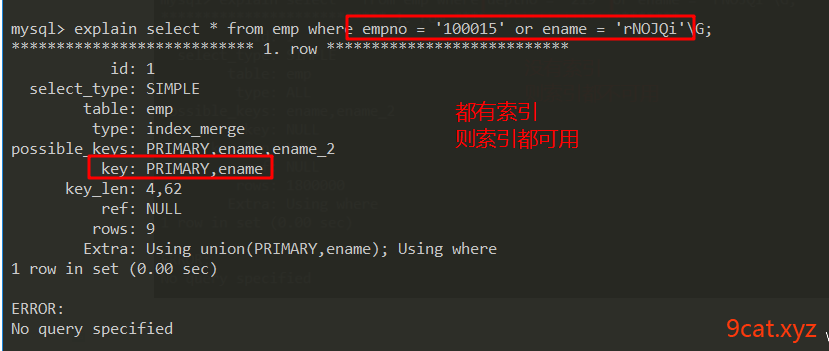
④or条件
or条件字段如果都有索引可用,则索引都可用;如果有其中一个字段索引不可用,则都不可用。