大型网站优化之mysql优化二
一、索引补充
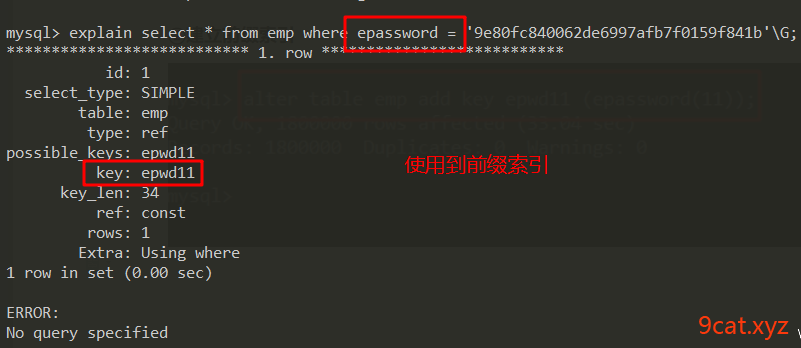
1、前缀索引
前缀 前边的一部分
列:班级里的同学
张三
李四
王五
赵六
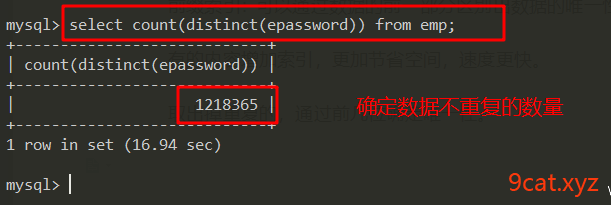
前缀索引:可以通过数据的前一部分区别出数据的唯一性,把这部分增加索引。比把字段所有的内容增加索引,更加节省空间,速度更快。
取出掉重复的,通过前几位确定唯一性。
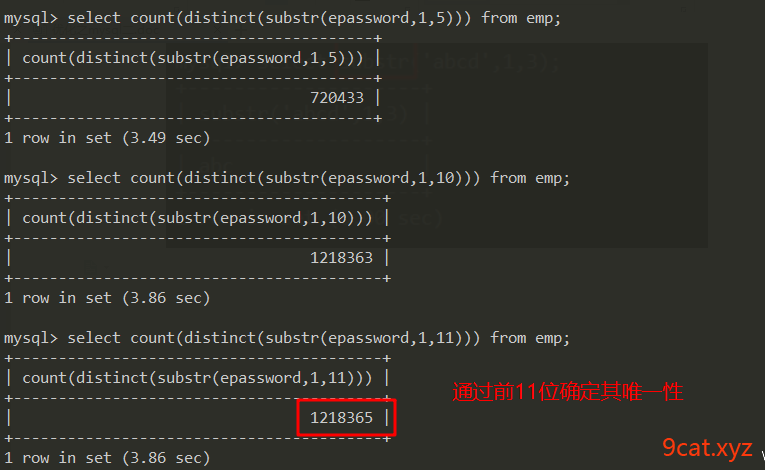
①确定建立索引前缀长度
语法:distinct()
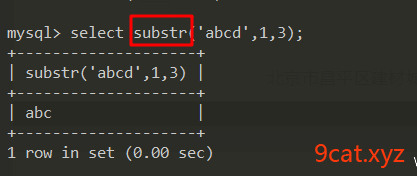
语法:substr(str,start,length)
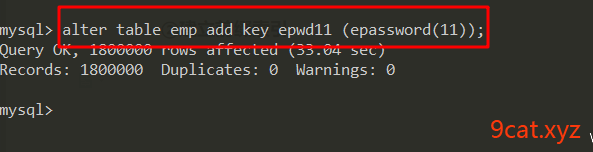
②建立前缀索引
语法:alter table 表名称 add key 索引名称(字段(前几位))
in条件索引使用
in条件 枚举 同时查询出多条(不连续的)
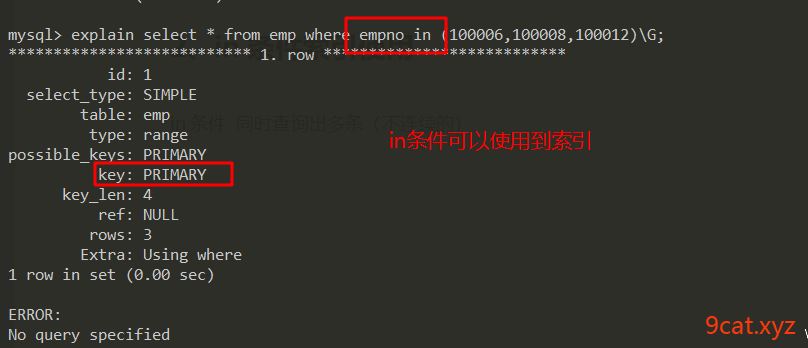
如果某个字段,经常使用到in条件进行查询。可以选择给此字段增加索引。in条件可以使用到索引。
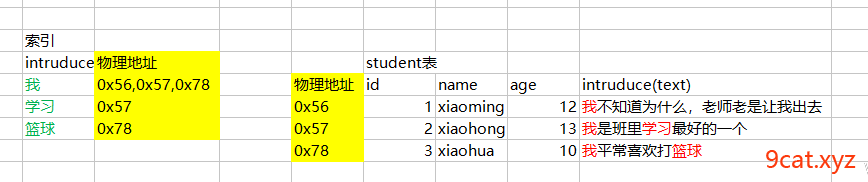
全文索引
文本类型 char varchar text
通过分词,然后给分词建立索引。
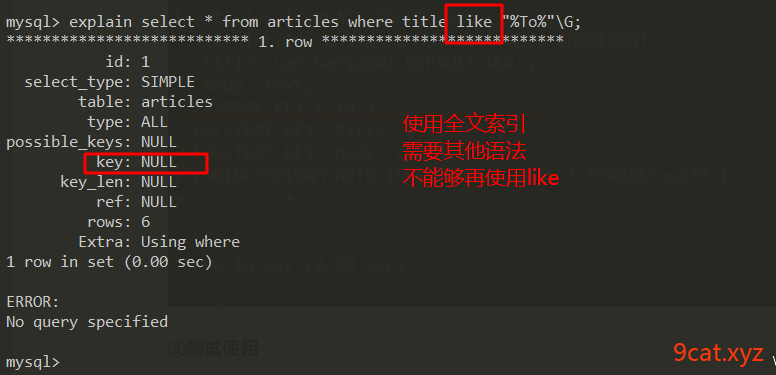
解决like查询(左固定),使用不到索引的问题。
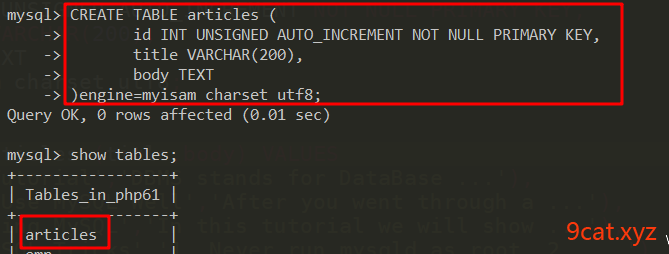
3.1 增加全文索引
①建立一个测试表articles,并写入数据
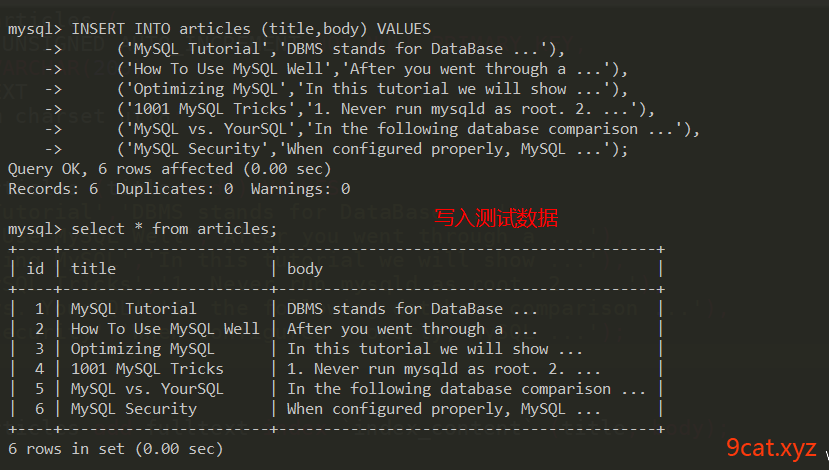
②增加索引
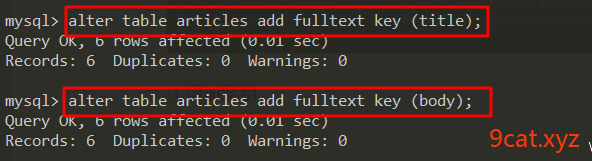
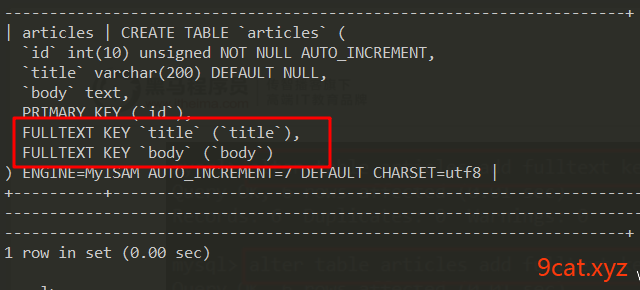
③测试使用
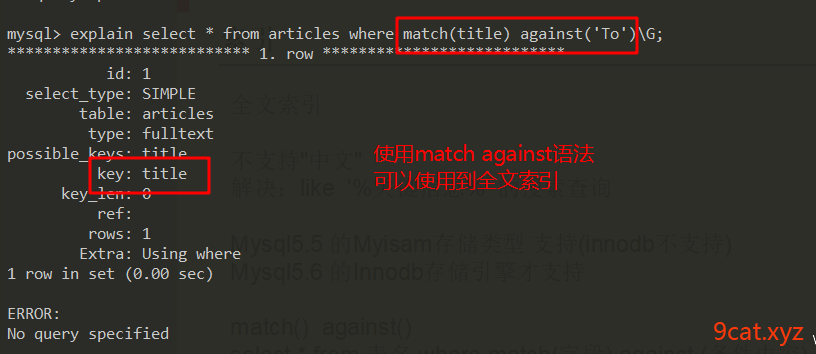
3.2 复合全文索引
①增加复合全文索引

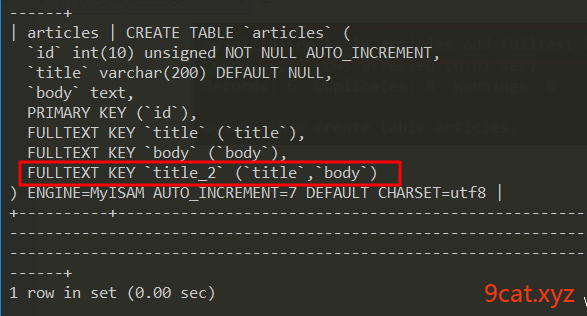
②测试使用
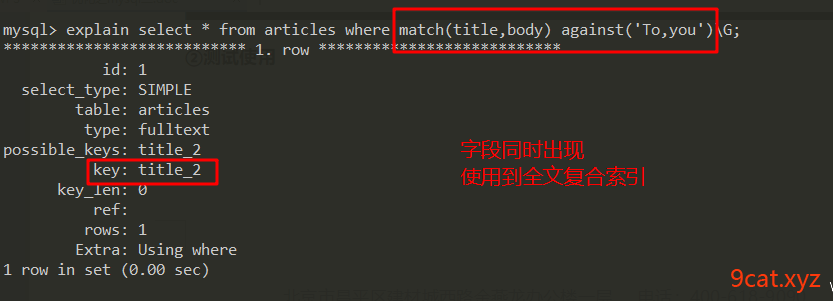
3.3 使用全文索引查询数据
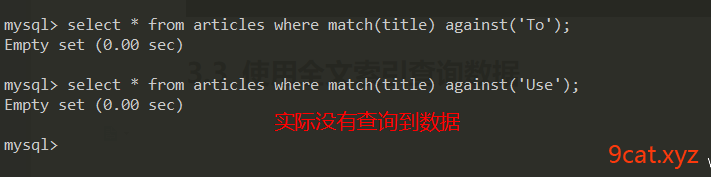
match against是查询全文索引的语法。
全文索引里没有给查询的关键词建立索引。mysql本身不会把经常使用的一些词汇建立索引。
在实际业务开发环境,经常使用到的单词,反而没有建立索引。不适用于使用需求。会选择一些第三方软件配合mysql实现全文索引技术和搜索引擎技术。
php + sphinx 分词技术 全文索引技术 搜索引擎技术
xunsearch
java + lucene solr
3.4 全文索引注意
①只支持文本类型 char varchar text
②mysql5.6以下 myisam支持
③分词不适合实际使用,不支持中文
④选择sphinx等第三方软件代替mysql的全文索引
4、分页优化
分页原理:集合sql语法 limit(skip,length);
在大数据量下的表,进行分页limit语法操作,出现分页skip太大,使用不到索引的情况。
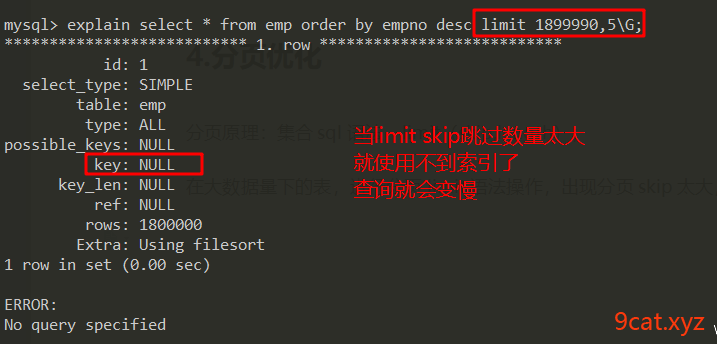
优化方案:
①进行数据的卡位操作
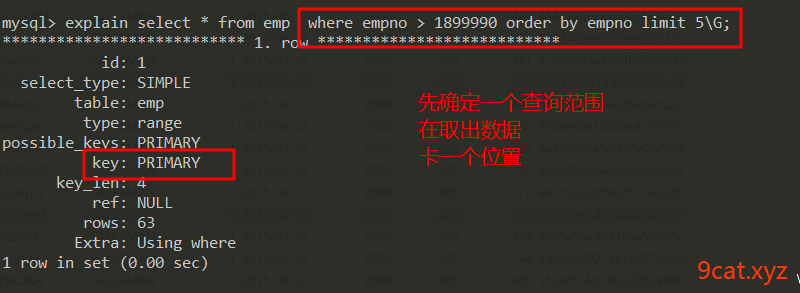
注意在进行where条件限制范围的时候,注意参数条件的起始值。
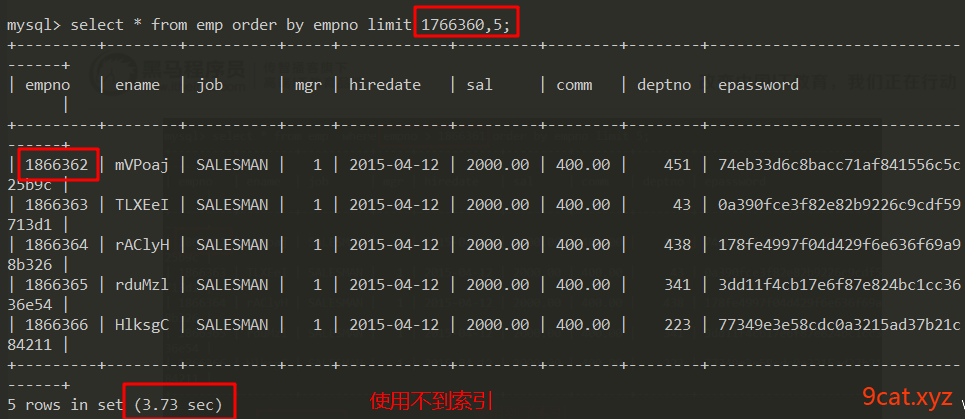
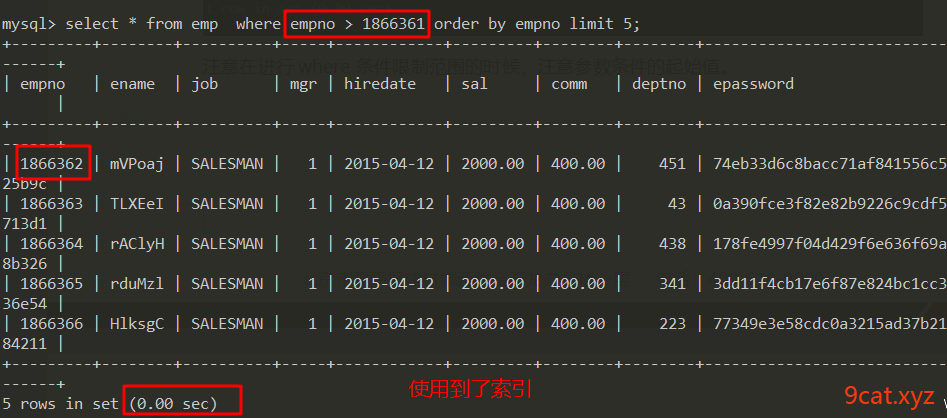
正常来说,数据表的主键id是自增和顺序的,所以skip跳过值和主键id是一致的。
以上列子,是因为id不是从1开始,所有要加上起始值。如果在数据表中,有删除的数据,主键id不连续,那么查询出来的结果,也就不一致。
分页优化,就是要把查询的limit范围,先通过where字段条件缩小,就可以使用索引了。
因为如果mysql认为查询索引之后,获取到的数据还是范围很大,就不会使用索引。
5、索引结构的类型(了解)
①聚集型索引
聚合 聚簇
数据文件和索引文件是在一起的
innodb .ibd
②非聚集型索引 非聚簇型索引
数据文件和索引文件是分离的
myisam .MYD .MYI
5.1 Myisam索引数据结构
主键索引
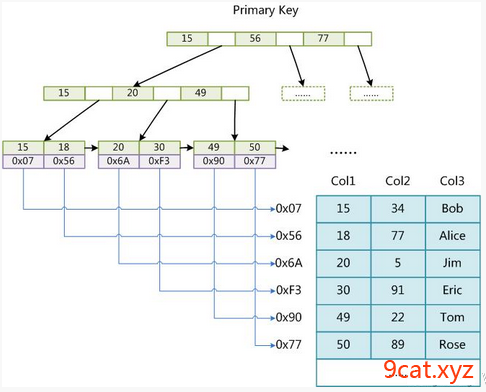
主键索引索引查询过程:
查询关键字=>主键索引=>物理地址 =>真实数据
非主键索引
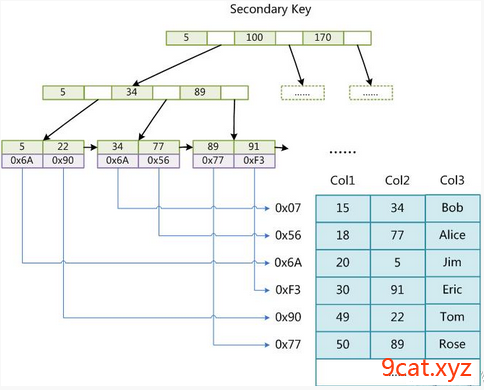
非主键索引索引查询过程:
查询关键字=>非主键索引=>物理地址=>真实数据
5.2 Innodb索引数据结构
主键索引
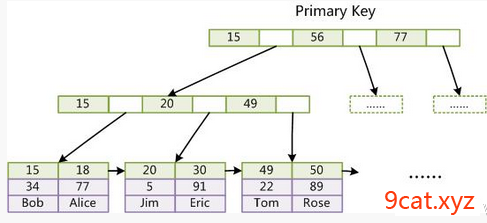
主键查询数据过程:
关键字=>主键索引=>真实数据
非主键索引
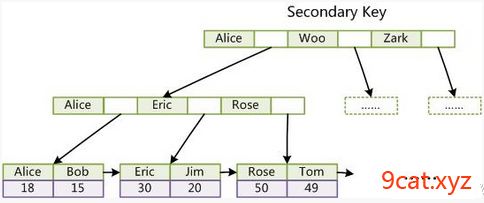
非主键查询数据过程:
关键字=>非主键索引=>主键索引=>真实数据
Tip:如果innodb没有主键索引,非主键索引如何使用呢?
记录一个数据的唯一值。如果没有主键,会生成一个rowid(唯一)。非主键索引就记录这个rowid。
https://segmentfault.com/q/1010000003856705
https://www.cnblogs.com/softidea/archive/2016/08/29/5816497.html
二、缓存设置
mysql中提供了缓存机制,可以通过对应的sql语句,把数据结果保存起来,之后直接返回缓存数据的结果即可。提高了查询速度。
1、具体使用
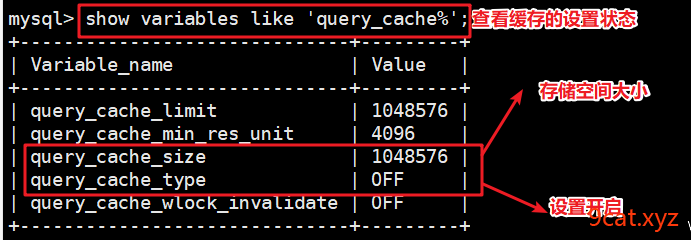
①查看并开启缓存
mysql > show variables like 'query_cache%';
在/etc/my.cnf 配置文件里修改
shell > vim /etc/my.cnf
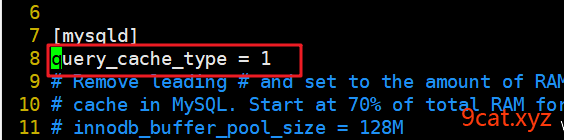
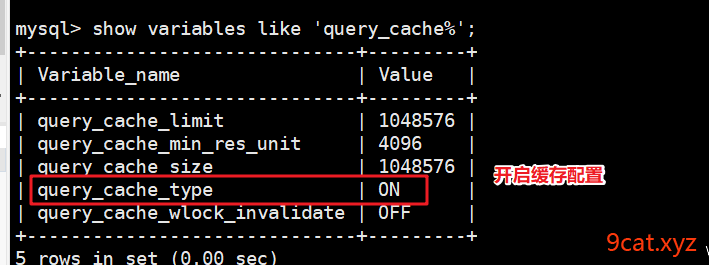
shell > service mysqld restart
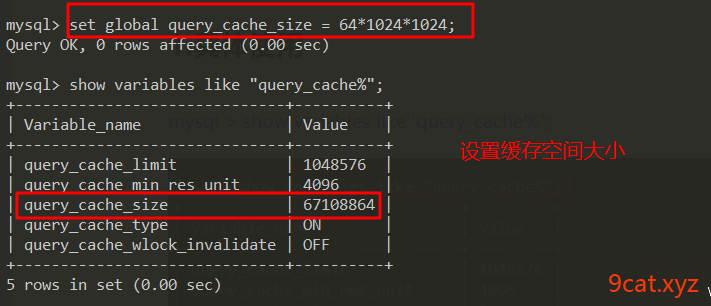
选做可以设置缓存的空间大小,单位B 字节
mysql > set global query_cache_size=64*1024*1024;
②测试查看使用
测试使用emp表,因为之前已经把字段基本都建立索引,如果想要测试效果,可以选择把某个字段删除索引,进行查看。
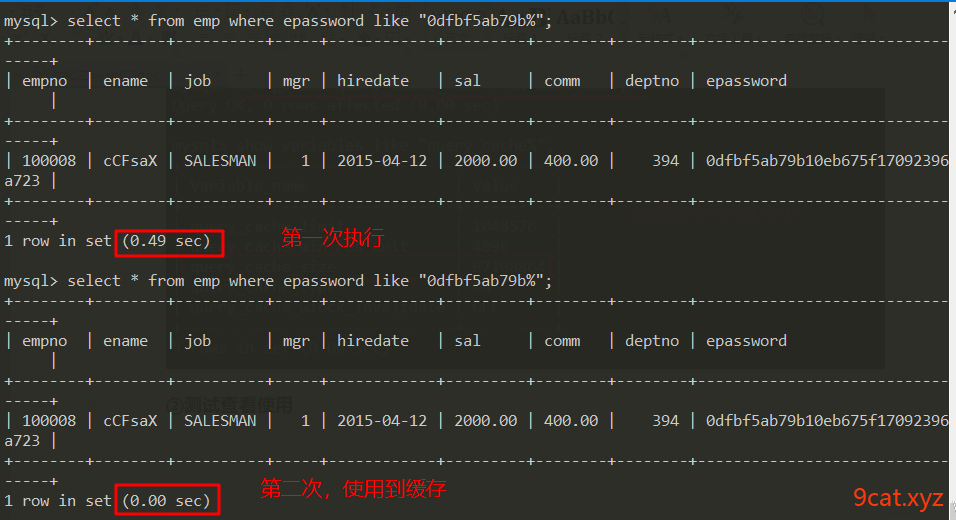
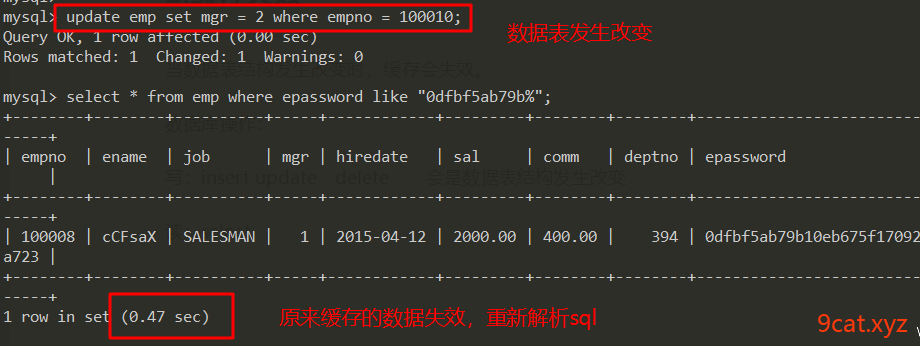
2、缓存失效
当数据表结构发生改变时,缓存会失效。
数据库操作:
写:insert update delete 会是数据表结构发生改变
读:select
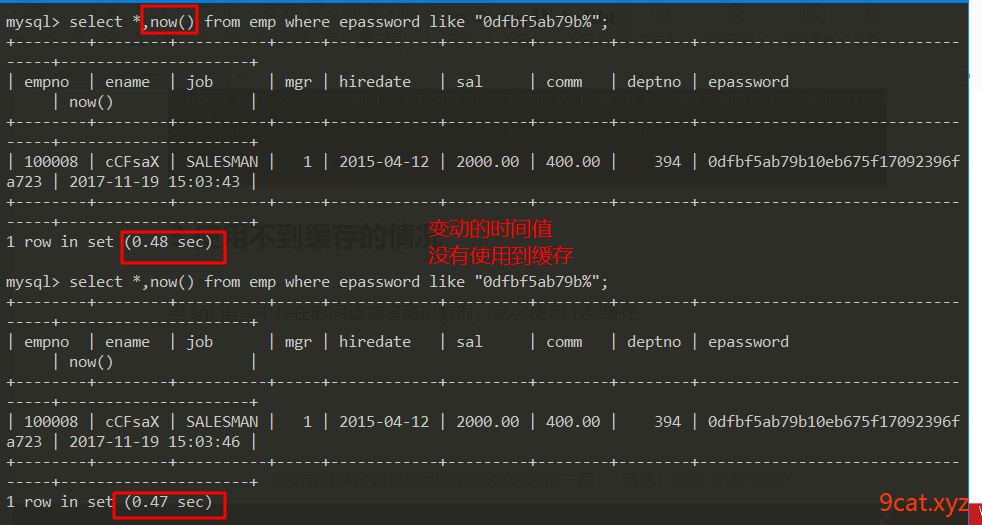
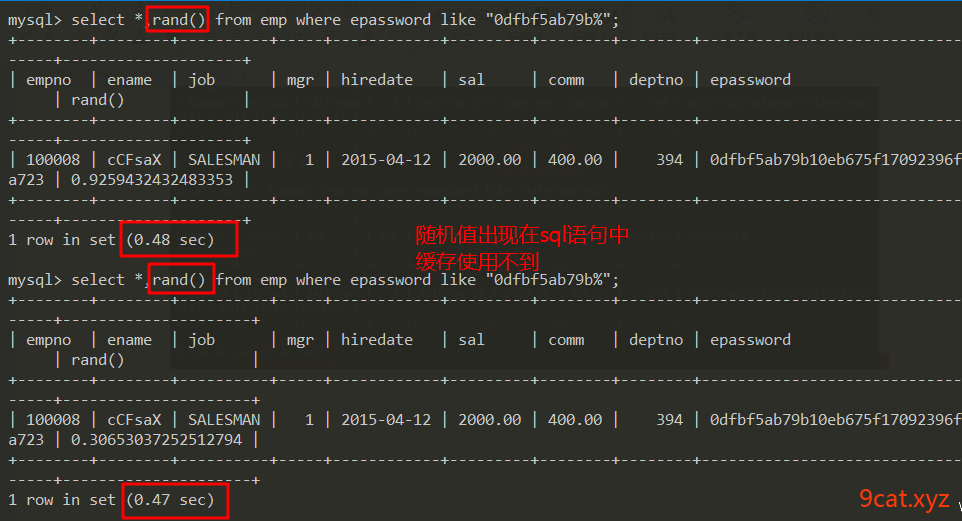
3、使用不到缓存的情况
当sql语句中存在时间值或者随机数时,就会使用不到缓存
now() rand()
4、生成多个缓存
由于sql语句大小写、空格等,会被认为是多条不同的sql语句,就会生成多个缓存
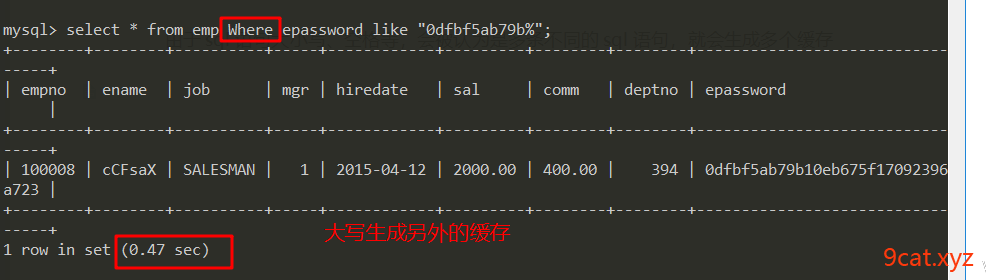
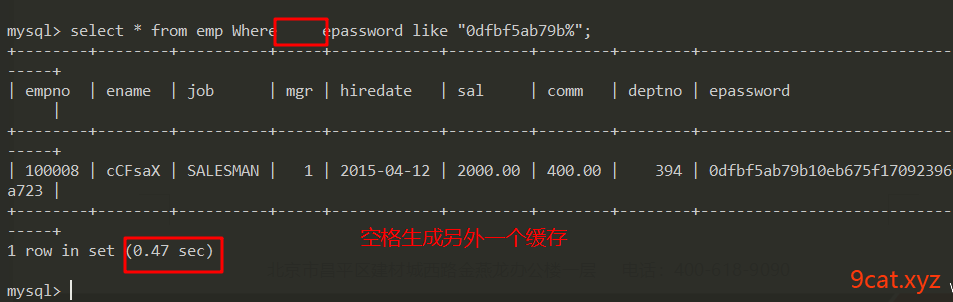
针对以上情况,在书写sql语句时,一定按照约定好的格式和规范。
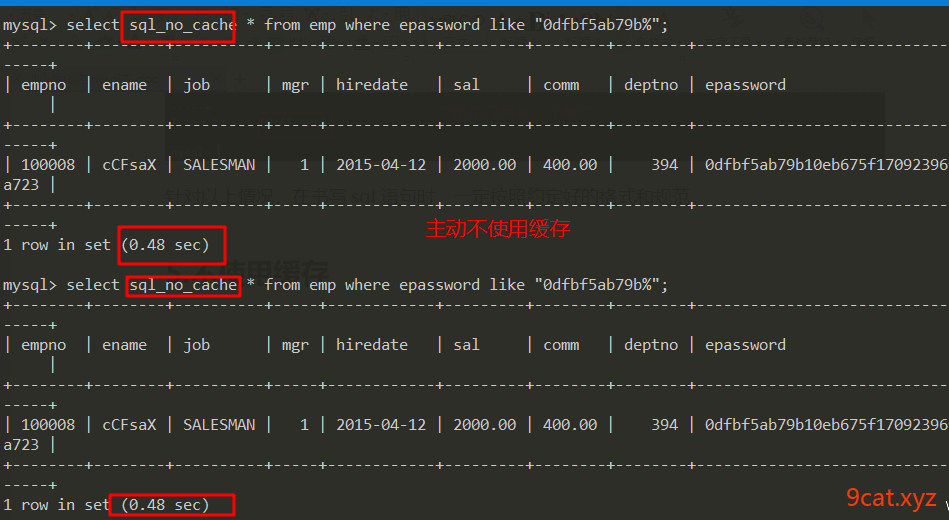
5、不使用缓存
使用sql_no_cache语法,不使用到缓存
6、缓存其他操作
①查看缓存使用的状态
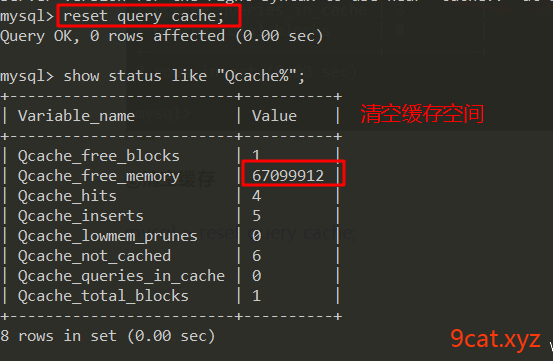
mysql > show status like 'Qcache%';
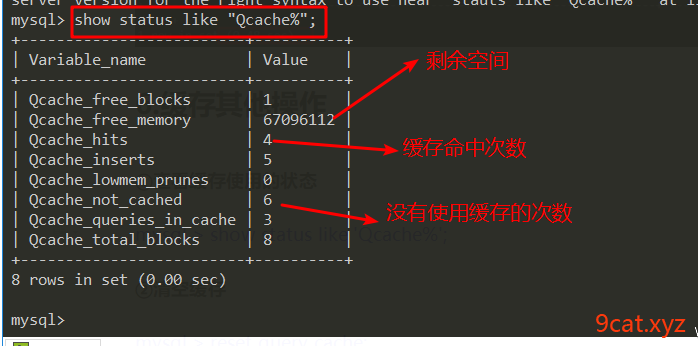
如果缓存命中率低。可能缓存空间设置太小。数据表更新频繁。
②清空缓存
mysql > reset query cache;
三、分表设计
在一般业务环境使用中,使用索引、缓存、内存缓存优化。能够满足大部分业务使用需要的速度。
随着业务发展,数据表中的数据量增加太快。百万级以上,千万级别亿级别时,单个数据表已经不能支撑业务需求了。数据表表活性大大降低,性能成指数下降,可以选择分区表的方式。把数据分配到多个数据表中,以提高数据的读写速度。
还有一种称呼叫做,分片 shareding
1、分区表类型区别
分片
分区、分表类型:
①逻辑分区 分表 真实还是一个表 逻辑分为多个 使用的sql语句和单表相同 mysql本身语法
②物理分表 把数据分配到几个真实数据表中,sql语句需要确定操作哪个表 手动建立分表 业务代码实现操作哪个分表
2、四种格式的逻辑分表
逻辑分区分类:
①取余方式 key/hash 会根据数据表的算法分配多个分表中
②条件方式 range/list 数据满足某一个分表的条件,就被分配到分表
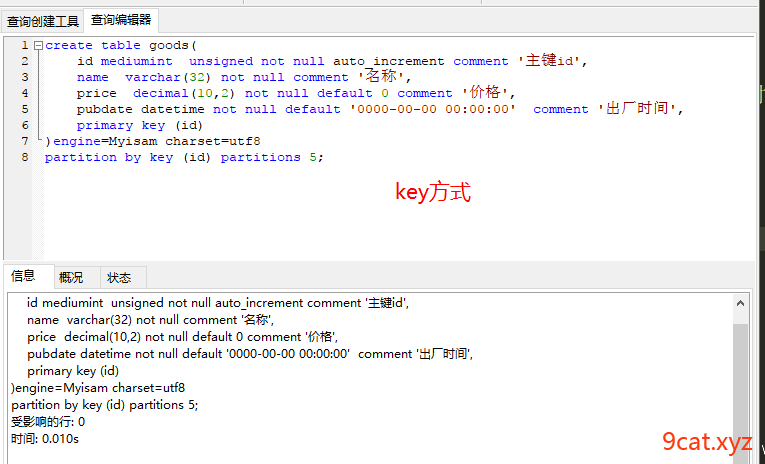
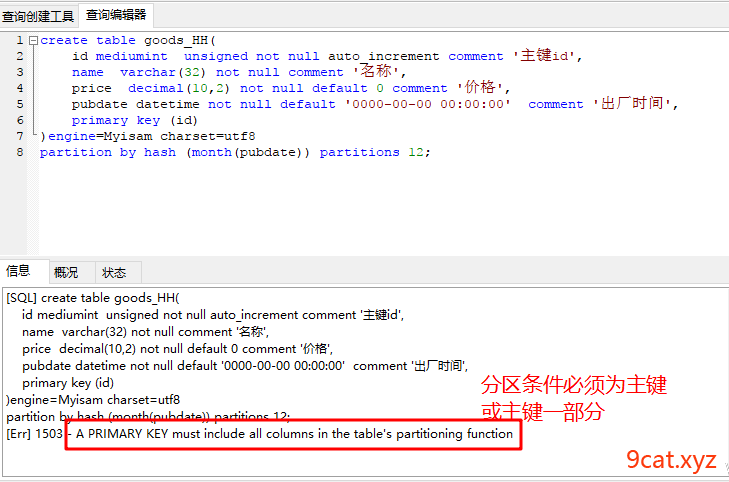
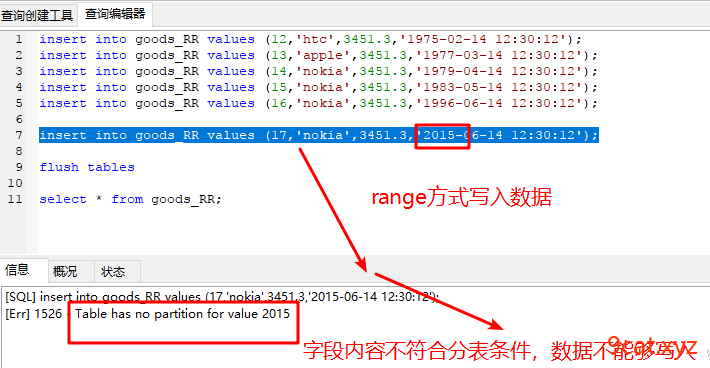
分表条件必须是主键或者是主键的一部分(联合主键)
2.1、key分表
语法:
create(
字段 类型
……
)
partition by key (字段) partitions 分区数目
①建立实现key方式分表
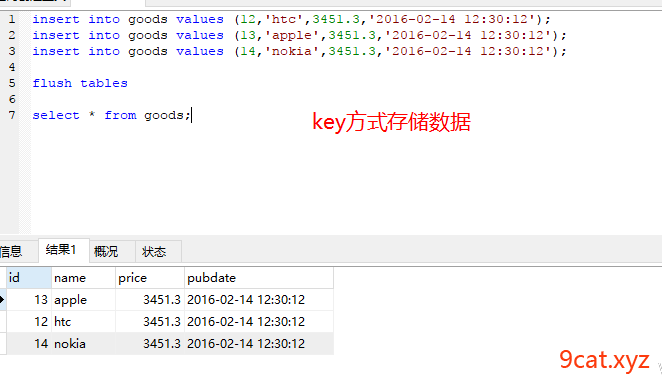
②写入查询数据查看
2.2、hash分表
语法:
create(
字段 类型
……
)
partition by hash(表达式(字段)) partitions 分区数目
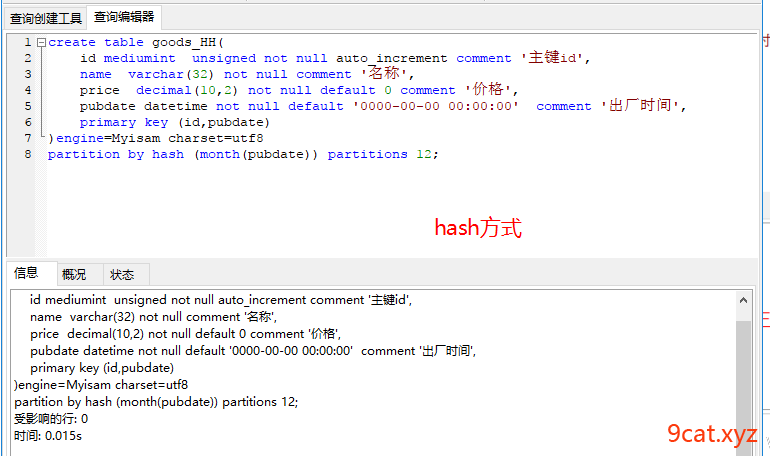
②写入查询数据查看
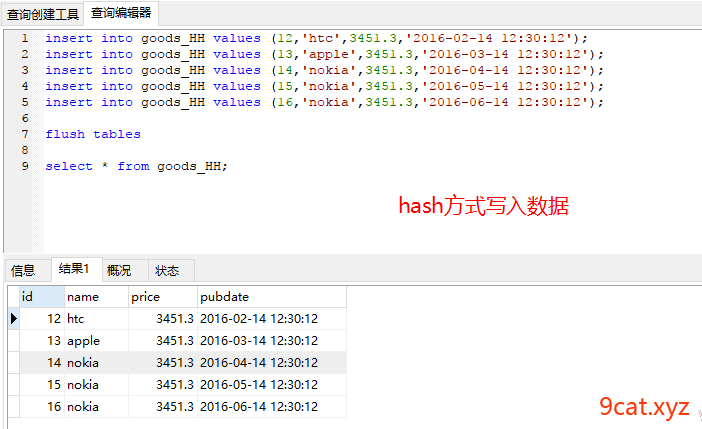
2.3、range分表
语法:
create(
字段 类型
……
)
partition by range(字段/表达式) (
partition 名称1 values less than (常量),
partition 名称2 values less than (常量),
partition 名称3 values less than (常量),
);
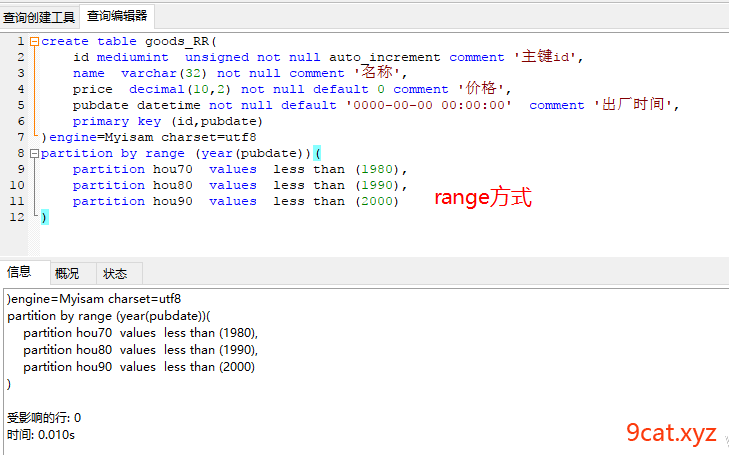
②写入查询数据
2.4、list分表
语法:
create(
字段 类型
……
)
partition by list(字段/表达式) (
partition 名称1 values in (列表1),
partition 名称2 values in (列表2),
partition 名称3 values in (列表3),
);
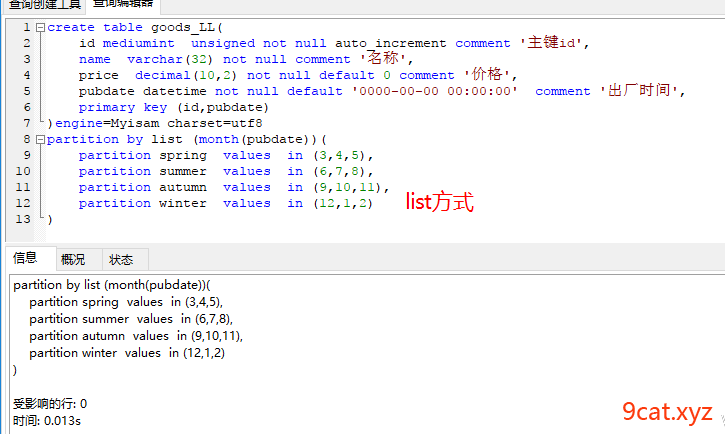
②写入查询数据查看
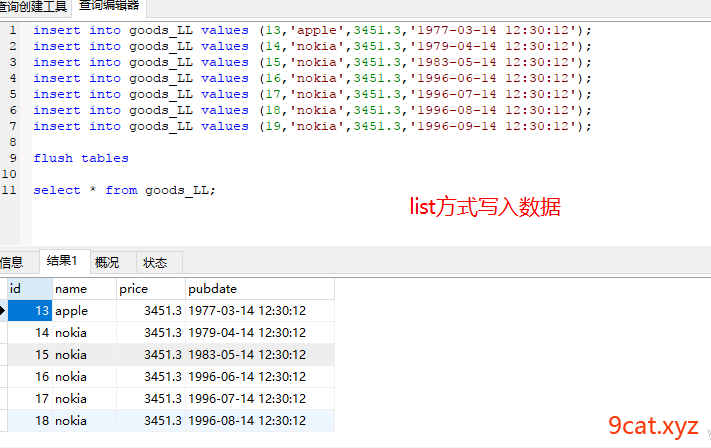
3、分表管理
数据表已经建立好,或者分区数据表后期需要增加或者删除表。可以对相应的数据表进行管理操作。
3.1、key/hash分表管理
语法:
求余(key/hash)分区:
增加:alter table 表名 add partition partitions 5;
减少:alter table 表名 coalesce partition 12;
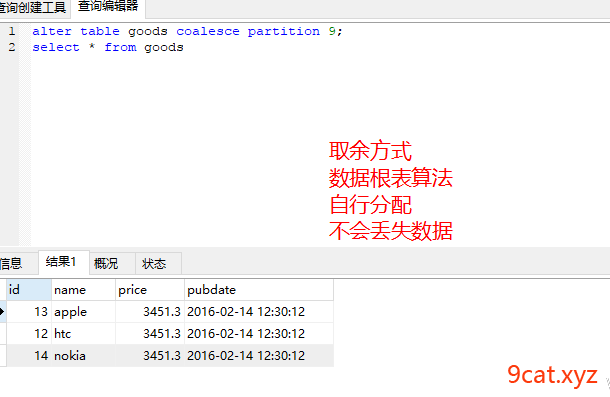
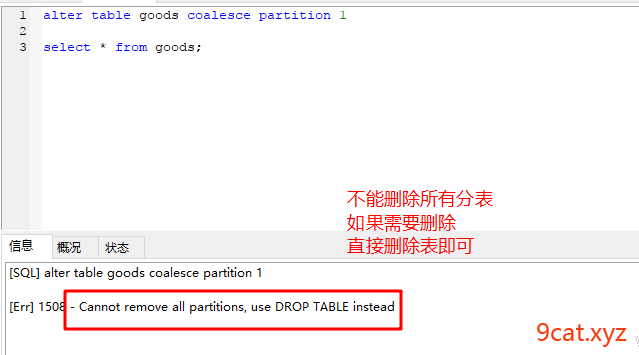
key/hash 方式,数据存储方式和业务联系(条件)不紧密
3.2、range/list分表管理
语法:
增加:
alter table 表名 add partition(
partition 名称 values less than (常量)
或
partition 名称 in (n,n,n)
);
减少:
alter table 表名 drop partition 分区名称;
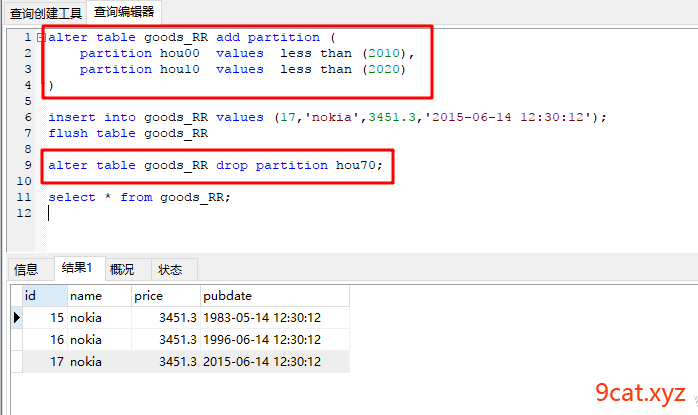
range/list方式,删除分区数据会丢失,和业务联系紧密。
4、物理分表设计
物理分表的方式:
①水平分表
②垂直分表
4.1、水平分表
把数据表进行横向切割,数据是完整的一行(row)。根据某个字段的取值范围。
分为emp1,emp2表。
例如:
在数据表中有多个年份的数据。经常使用的数据是今年的。
根据年份分为:
emp_2015 emp_2016 emp_2017
通过emp的empno的id分表
前10000条数据 分为emp_1
10000条-20000条 分为emp_2
。。。。。。
4.2、垂直分表
垂直分表,将数据进行竖向切割。
例如:
user表
id username password sex hobby cardid
需求:如果进行用户登录操作,需要查询id username password
解决方案:把user表通过常用的字段和不太常用的字段,分割为两个表
user表
id username password
user_ext表
id sex hobby cardid user_id
以上分表可以提高登录速度。
根据业务需求,选择对应的分表方式。
四、慢查询日志设置
慢查询:如果执行的sql语句,返回数据时间,大于设置的设置(规定的时间),这个sql语句就被认为是一个慢查询。
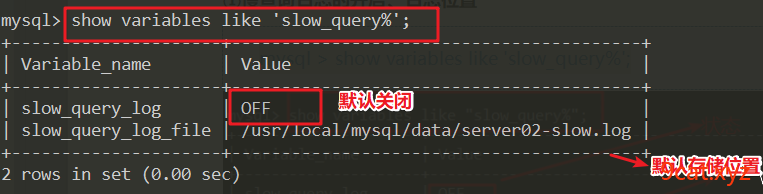
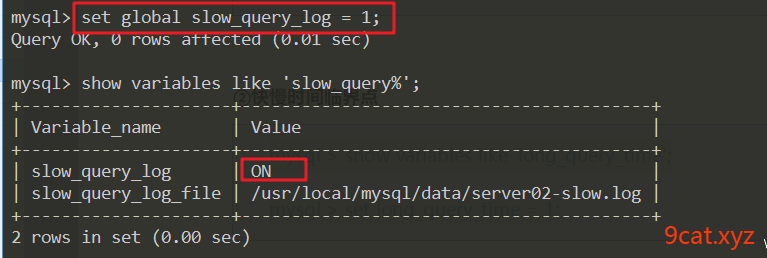
①慢查询日志的开启、日志位置
mysql > show variables like 'slow_query%';
mysql > set global slow_query_log = 1;
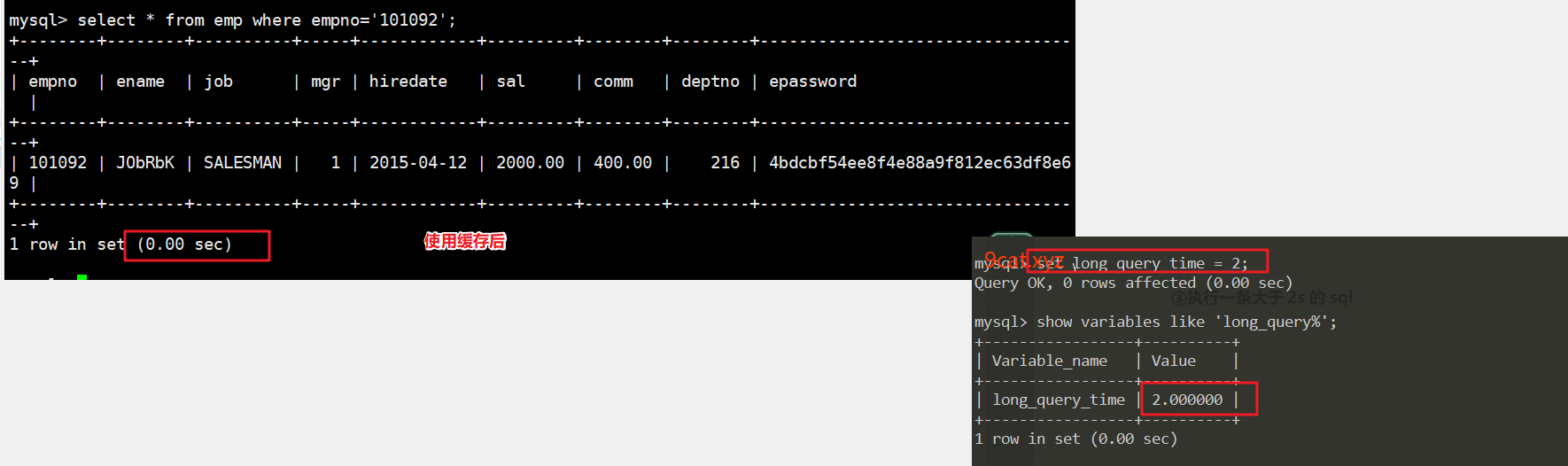
②快慢时间临界点
mysql > show variables like 'long_query_time';
mysql > set long_query_time = 2;
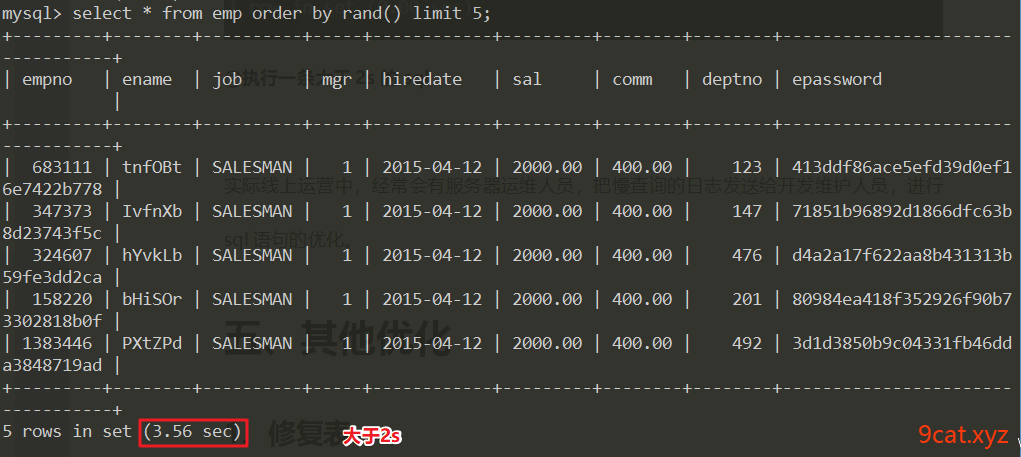
③执行一条大于2s的sql
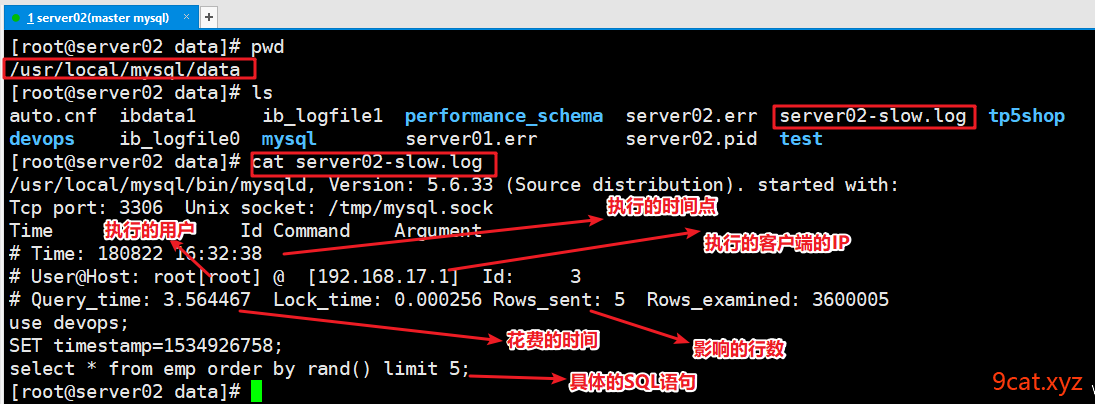
实际线上运营中,经常会有服务器运维人员,把慢查询的日志发送给开发维护人员,进行sql语句的优化。
其他优化
修复表
在长期的数据更改过程中,索引文件和数据文件,都将产生空洞,形成碎片,我们可以通过一个操作(不产生对数据实质影响的操作)来修改表,修复表语法操作。
①新建一个testnum表
②增加模拟数据
复制产生多条数据
③删除表数据

通过修复表语句,进行表的碎片修复。
语法:optimize table 表名;
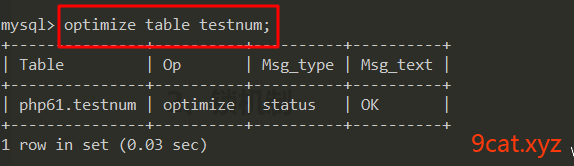
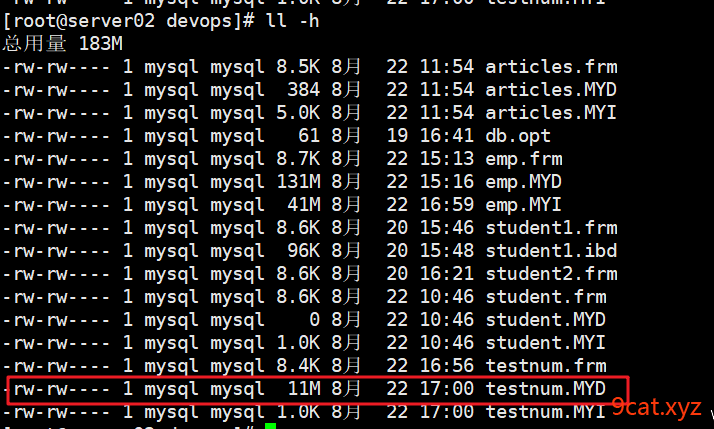
修复表碎片和空洞操作,是为了减少遍历时间空间,提供查询速度。
修复表碎片需要时间,不要经常做此操作。可以周期性执行。
锁机制
lock
锁 占用(保护)的作用。
锁是一个标识,表示这个资源已经被占用,需等待。
锁的实际使用,就是为了能够让用户进行等待操作。阻塞用户的操作。
操作系统原理 进程 锁
语法:lock table 表名称 锁定方式
unlock tables
锁类型:
读锁 共享锁 S锁 锁定之后可读不可写
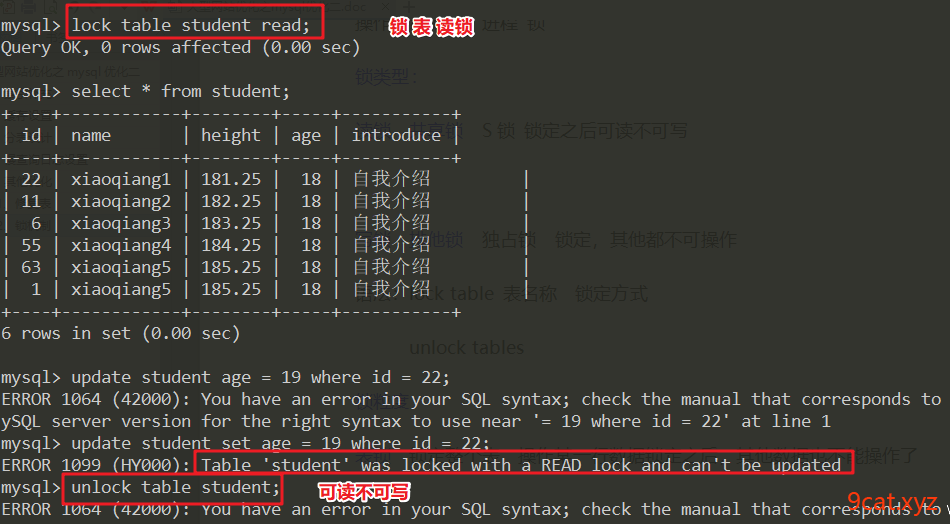
写锁 排他锁 独占锁 锁定,其他都不可操作
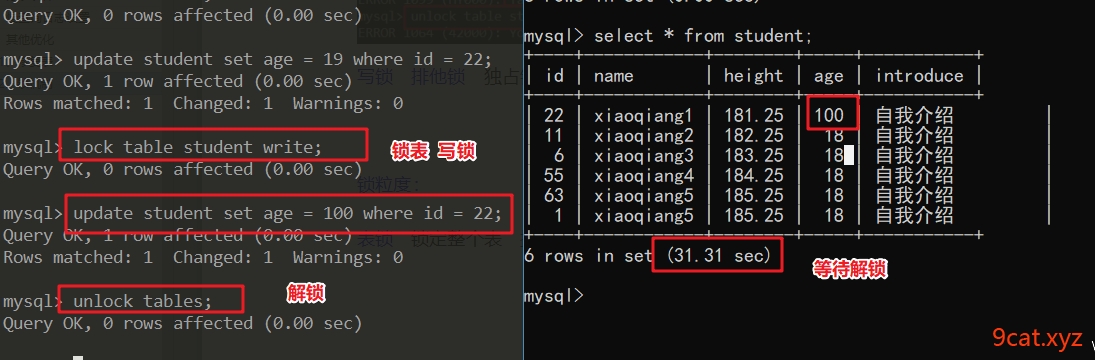
锁粒度:
表锁 锁定整个表 操作某一行数据锁定之后,其他数据也不能操作了
行锁 innodb 行锁定 锁定的是索引
语法:
begin;
执行语句;
commit;
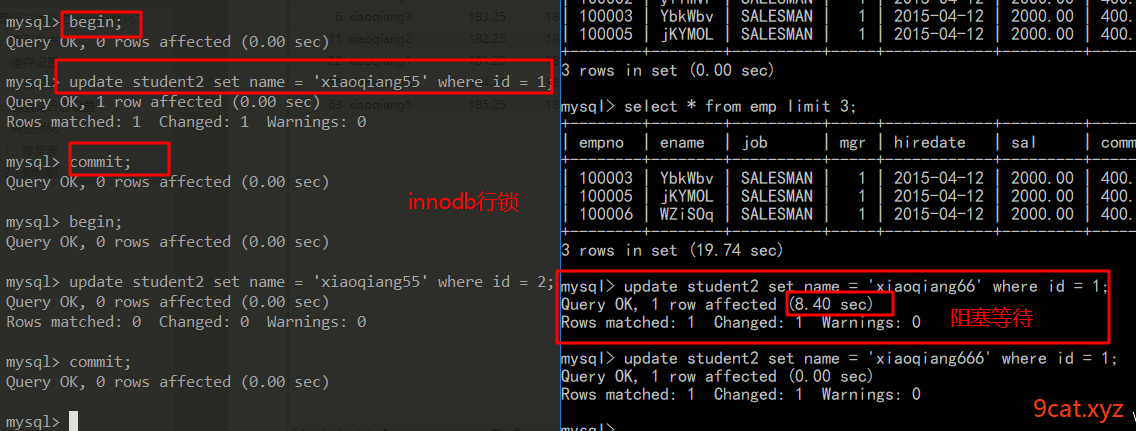
实际小案列分析
如果并发读写过程中,不进行锁操作,排队操作,会发生什么?
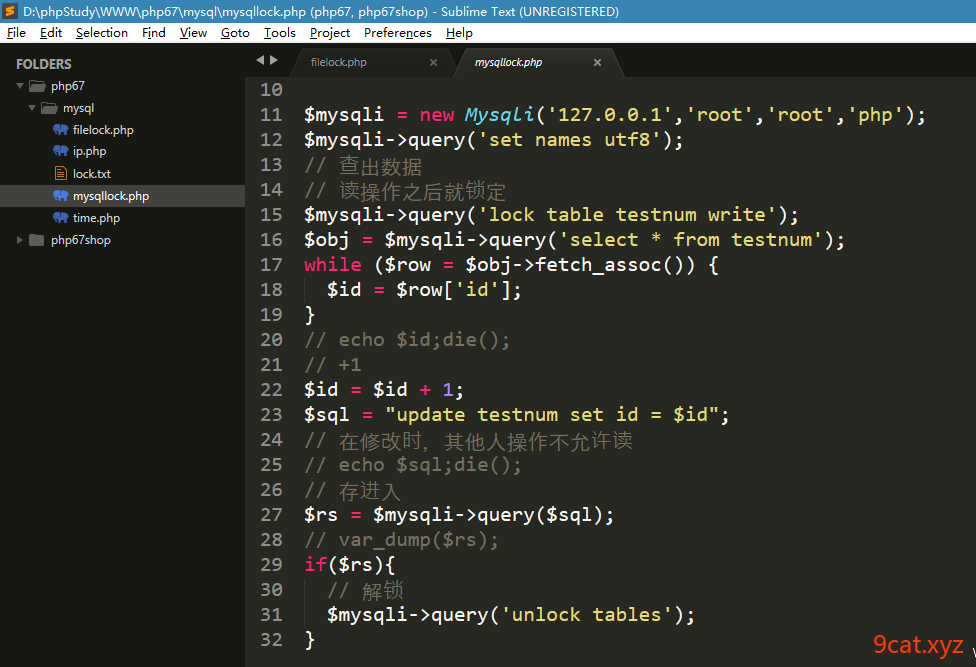
现在的数据值
使用ab.exe进行模拟并发测试
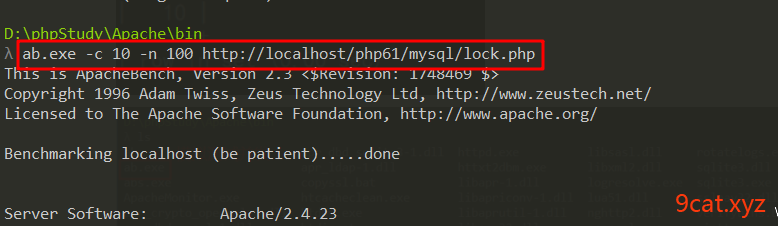
-c 并发数
-n 总请求数
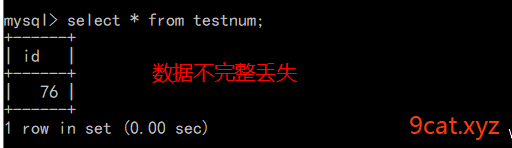
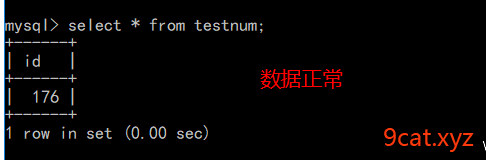
刚才的mysql操作可以实现并发数据丢失的问题,同时有另外问题,锁表其他操作也不能过进行了。实际开发中,可以使用文件锁的方式。通过文件的标识来进行确定是否具有操作权限和资格。
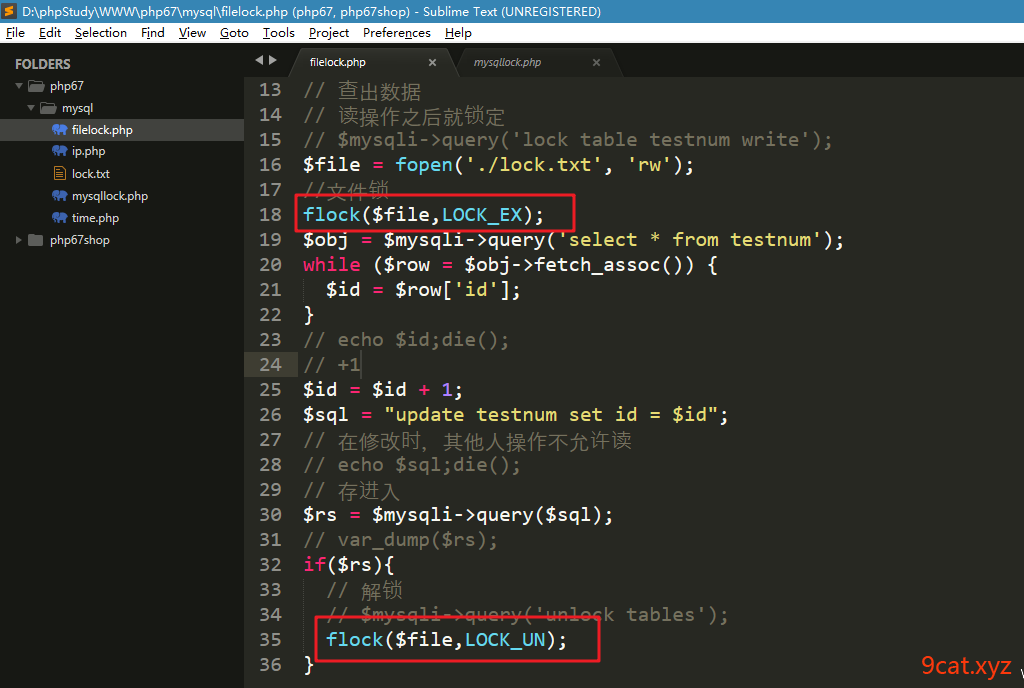
锁机制,就是为了防止用户进行并发操作时,出现数据不完整和不一致的情况。让操作一个一个执行,进行了阻塞排队操作。
实际应用:
例如:抢购出现了超卖现象,如何避免?
①把剩余的商品数量设置为unsigned(没有负数)
②在下订单抢购的时候,使用事务机制和锁机制实现